Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Variance of Unbiased Online Recurrent Optimization
Paper and Code
Feb 06, 2019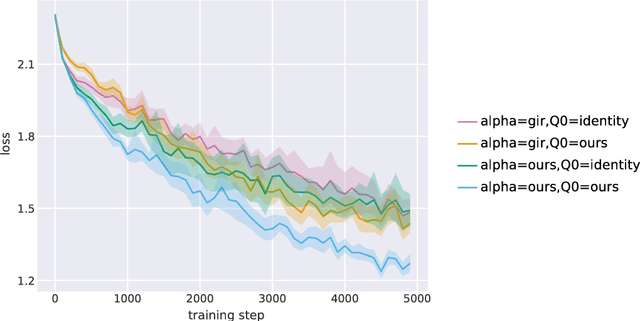
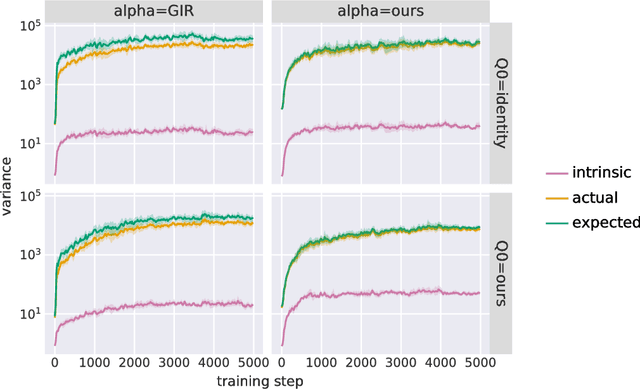
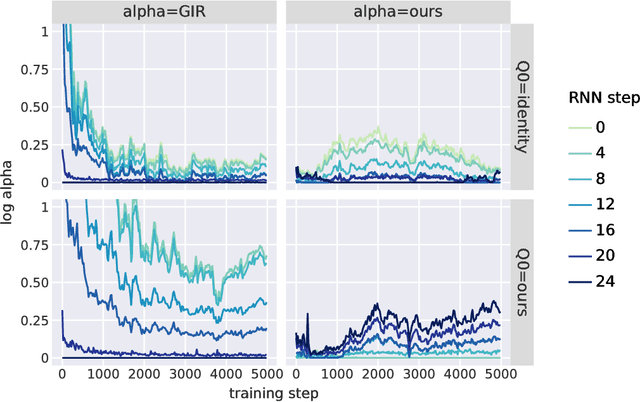
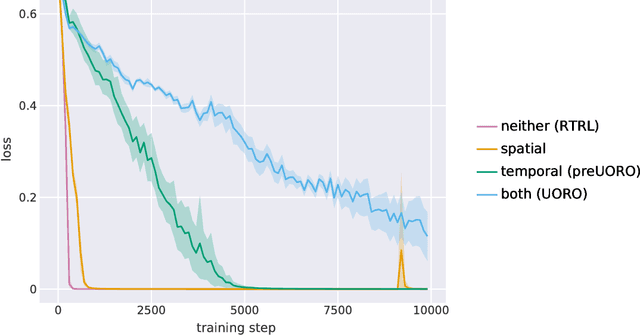
The recently proposed Unbiased Online Recurrent Optimization algorithm (UORO, arXiv:1702.05043) uses an unbiased approximation of RTRL to achieve fully online gradient-based learning in RNNs. In this work we analyze the variance of the gradient estimate computed by UORO, and propose several possible changes to the method which reduce this variance both in theory and practice. We also contribute significantly to the theoretical and intuitive understanding of UORO (and its existing variance reduction technique), and demonstrate a fundamental connection between its gradient estimate and the one that would be computed by REINFORCE if small amounts of noise were added to the RNN's hidden units.
View paper on