 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the role of depth predictions for 3D human pose estimation
Paper and Code
Mar 03, 2021


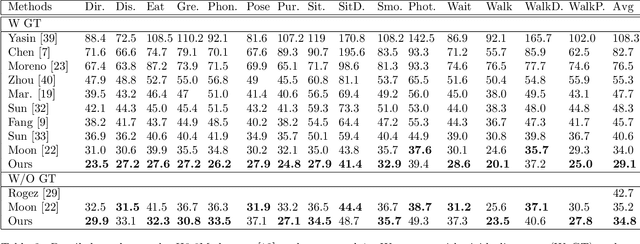
Following the successful application of deep convolutional neural networks to 2d human pose estimation, the next logical problem to solve is 3d human pose estimation from monocular images. While previous solutions have shown some success, they do not fully utilize the depth information from the 2d inputs. With the goal of addressing this depth ambiguity, we build a system that takes 2d joint locations as input along with their estimated depth value and predicts their 3d positions in camera coordinates. Given the inherent noise and inaccuracy from estimating depth maps from monocular images, we perform an extensive statistical analysis showing that given this noise there is still a statistically significant correlation between the predicted depth values and the third coordinate of camera coordinates. We further explain how the state-of-the-art results we achieve on the H3.6M validation set are due to the additional input of depth. Notably, our results are produced on neural network that accepts a low dimensional input and be integrated into a real-time system. Furthermore, our system can be combined with an off-the-shelf 2d pose detector and a depth map predictor to perform 3d pose estimation in the wild.