 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the relationship between class selectivity, dimensionality, and robustness
Paper and Code
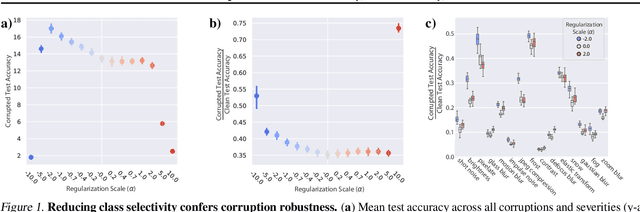
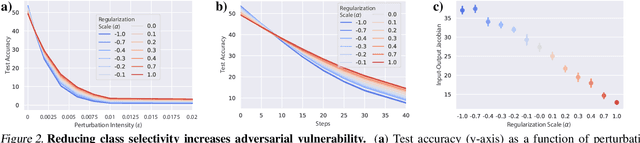
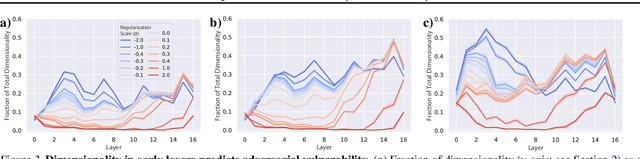
While the relative trade-offs between sparse and distributed representations in deep neural networks (DNNs) are well-studied, less is known about how these trade-offs apply to representations of semantically-meaningful information. Class selectivity, the variability of a unit's responses across data classes or dimensions, is one way of quantifying the sparsity of semantic representations. Given recent evidence showing that class selectivity can impair generalization, we sought to investigate whether it also confers robustness (or vulnerability) to perturbations of input data. We found that mean class selectivity predicts vulnerability to naturalistic corruptions; networks regularized to have lower levels of class selectivity are more robust to corruption, while networks with higher class selectivity are more vulnerable to corruption, as measured using Tiny ImageNetC and CIFAR10C. In contrast, we found that class selectivity increases robustness to multiple types of gradient-based adversarial attacks. To examine this difference, we studied the dimensionality of the change in the representation due to perturbation, finding that decreasing class selectivity increases the dimensionality of this change for both corruption types, but with a notably larger increase for adversarial attacks. These results demonstrate the causal relationship between selectivity and robustness and provide new insights into the mechanisms of this relationship.