 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Omnipresence of Spurious Local Minima in Certain Neural Network Training Problems
Paper and Code
Feb 23, 2022
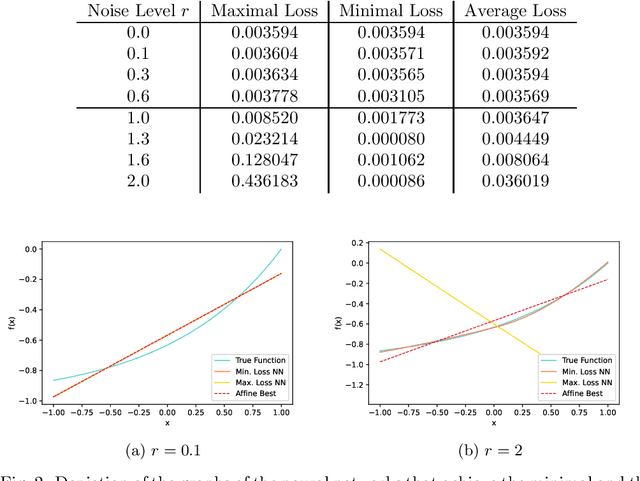
We study the loss landscape of training problems for deep artificial neural networks with a one-dimensional real output whose activation functions contain an affine segment and whose hidden layers have width at least two. It is shown that such problems possess a continuum of spurious (i.e., not globally optimal) local minima for all target functions that are not affine. In contrast to previous works, our analysis covers all sampling and parameterization regimes, general differentiable loss functions, arbitrary continuous nonpolynomial activation functions, and both the finite- and infinite-dimensional setting. It is further shown that the appearance of the spurious local minima in the considered training problems is a direct consequence of the universal approximation theorem and that the underlying mechanisms also cause, e.g., Lp-best approximation problems to be ill-posed in the sense of Hadamard for all networks that do not have a dense image. The latter result also holds without the assumption of local affine linearity and without any conditions on the hidden layers. The paper concludes with a numerical experiment which demonstrates that spurious local minima can indeed affect the convergence behavior of gradient-based solution algorithms in practice.