 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Neural Tangent Kernel Analysis of Randomly Pruned Wide Neural Networks
Paper and Code
Apr 06, 2022

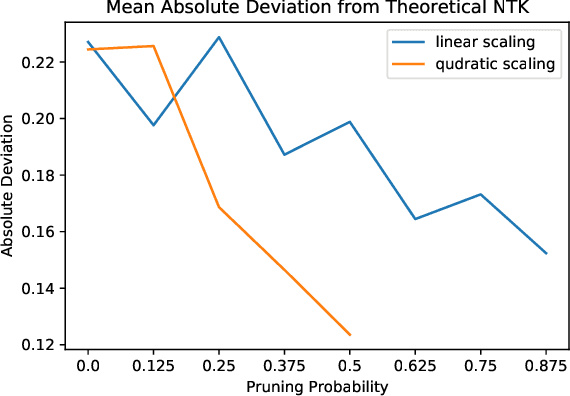
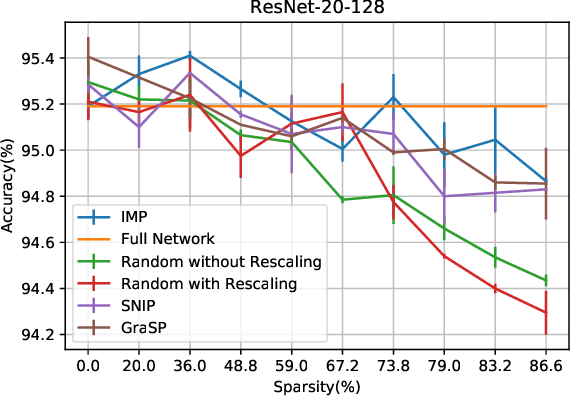
We study the behavior of ultra-wide neural networks when their weights are randomly pruned at the initialization, through the lens of neural tangent kernels (NTKs). We show that for fully-connected neural networks when the network is pruned randomly at the initialization, as the width of each layer grows to infinity, the empirical NTK of the pruned neural network converges to that of the original (unpruned) network with some extra scaling factor. Further, if we apply some appropriate scaling after pruning at the initialization, the empirical NTK of the pruned network converges to the exact NTK of the original network, and we provide a non-asymptotic bound on the approximation error in terms of pruning probability. Moreover, when we apply our result to an unpruned network (i.e., we set the probability of pruning a given weight to be zero), our analysis is optimal up to a logarithmic factor in width compared with the result in \cite{arora2019exact}. We conduct experiments to validate our theoretical results. We further test our theory by evaluating random pruning across different architectures via image classification on MNIST and CIFAR-10 and compare its performance with other pruning strategies.