 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Multilingual Ability of Decoder-based Pre-trained Language Models: Finding and Controlling Language-Specific Neurons
Paper and Code
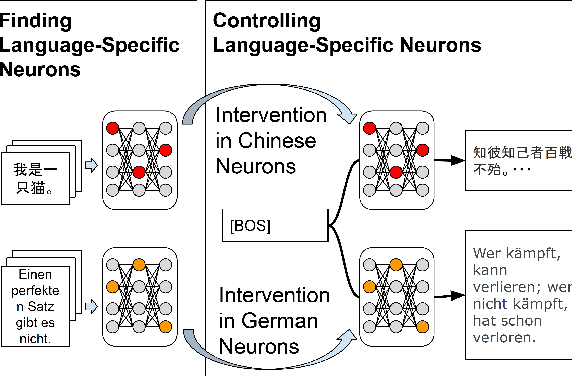
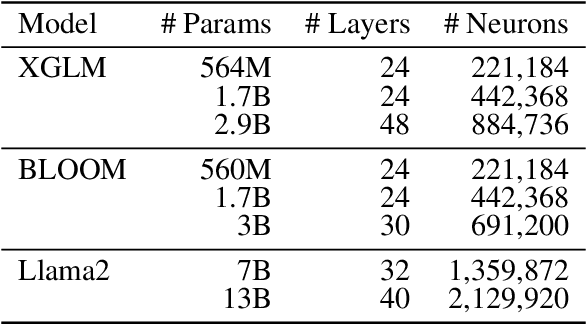
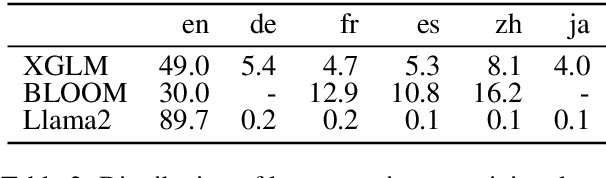
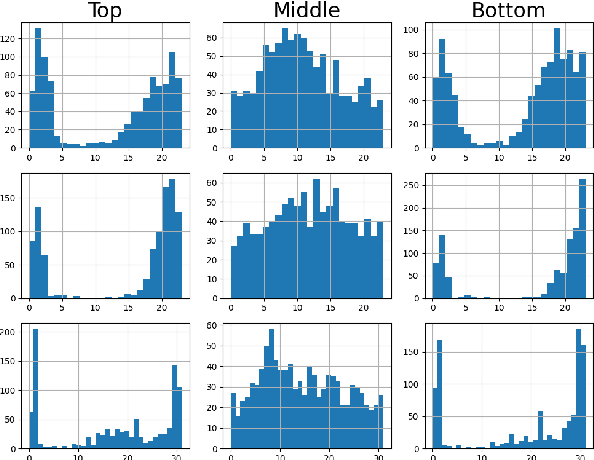
Current decoder-based pre-trained language models (PLMs) successfully demonstrate multilingual capabilities. However, it is unclear how these models handle multilingualism. We analyze the neuron-level internal behavior of multilingual decoder-based PLMs, Specifically examining the existence of neurons that fire ``uniquely for each language'' within decoder-only multilingual PLMs. We analyze six languages: English, German, French, Spanish, Chinese, and Japanese, and show that language-specific neurons are unique, with a slight overlap (< 5%) between languages. These neurons are mainly distributed in the models' first and last few layers. This trend remains consistent across languages and models. Additionally, we tamper with less than 1% of the total neurons in each model during inference and demonstrate that tampering with a few language-specific neurons drastically changes the probability of target language occurrence in text generation.