Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Maximum Mutual Information Capacity of Neural Architectures
Paper and Code
Jun 10, 2020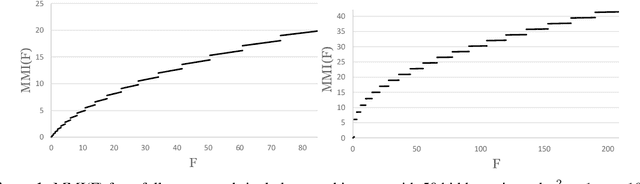
We derive the closed-form expression of the maximum mutual information - the maximum value of $I(X;Z)$ obtainable via training - for a broad family of neural network architectures. The quantity is essential to several branches of machine learning theory and practice. Quantitatively, we show that the maximum mutual information for these families all stem from generalizations of a single catch-all formula. Qualitatively, we show that the maximum mutual information of an architecture is most strongly influenced by the width of the smallest layer of the network - the "information bottleneck" in a different sense of the phrase, and by any statistical invariances captured by the architecture.
View paper on