 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Locality of the Natural Gradient for Deep Learning
Paper and Code
May 21, 2020

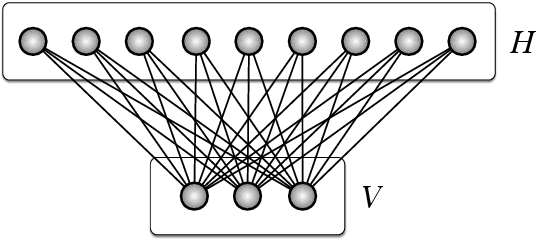

We study the natural gradient method for learning in deep Bayesian networks, including neural networks. There are two natural geometries associated with such learning systems consisting of visible and hidden units. One geometry is related to the full system, the other one to the visible sub-system. These two geometries imply different natural gradients. In a first step, we demonstrate a great simplification of the natural gradient with respect to the first geometry, due to locality properties of the Fisher information matrix. This simplification does not directly translate to a corresponding simplification with respect to the second geometry. We develop the theory for studying the relation between the two versions of the natural gradient and outline a method for the simplification of the natural gradient with respect to the second geometry based on the first one. This method suggests to incorporate a recognition model as an auxiliary model for the efficient application of the natural gradient method in deep networks.