 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization Mystery in Deep Learning
Paper and Code
Mar 31, 2022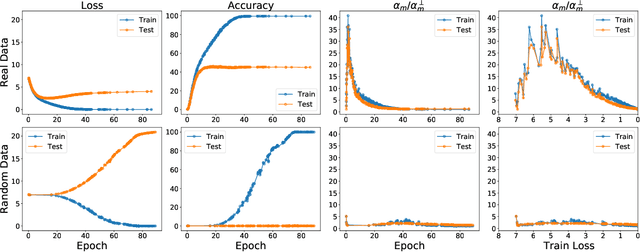
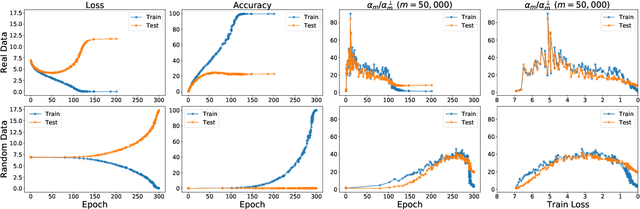
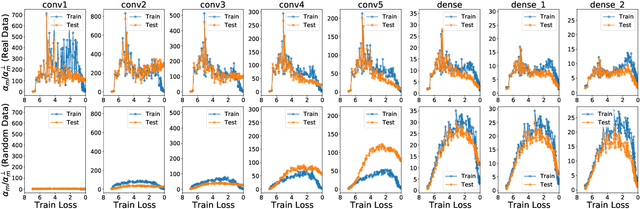
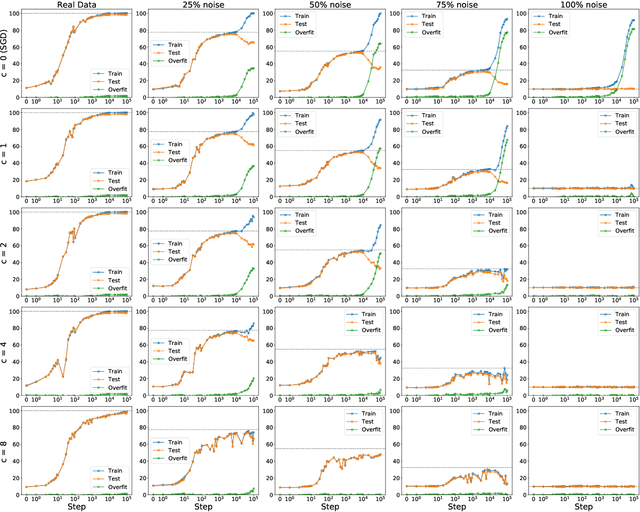
The generalization mystery in deep learning is the following: Why do over-parameterized neural networks trained with gradient descent (GD) generalize well on real datasets even though they are capable of fitting random datasets of comparable size? Furthermore, from among all solutions that fit the training data, how does GD find one that generalizes well (when such a well-generalizing solution exists)? We argue that the answer to both questions lies in the interaction of the gradients of different examples during training. Intuitively, if the per-example gradients are well-aligned, that is, if they are coherent, then one may expect GD to be (algorithmically) stable, and hence generalize well. We formalize this argument with an easy to compute and interpretable metric for coherence, and show that the metric takes on very different values on real and random datasets for several common vision networks. The theory also explains a number of other phenomena in deep learning, such as why some examples are reliably learned earlier than others, why early stopping works, and why it is possible to learn from noisy labels. Moreover, since the theory provides a causal explanation of how GD finds a well-generalizing solution when one exists, it motivates a class of simple modifications to GD that attenuate memorization and improve generalization. Generalization in deep learning is an extremely broad phenomenon, and therefore, it requires an equally general explanation. We conclude with a survey of alternative lines of attack on this problem, and argue that the proposed approach is the most viable one on this basis.