 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficacy of Co-Attention Transformer Layers in Visual Question Answering
Paper and Code
Jan 11, 2022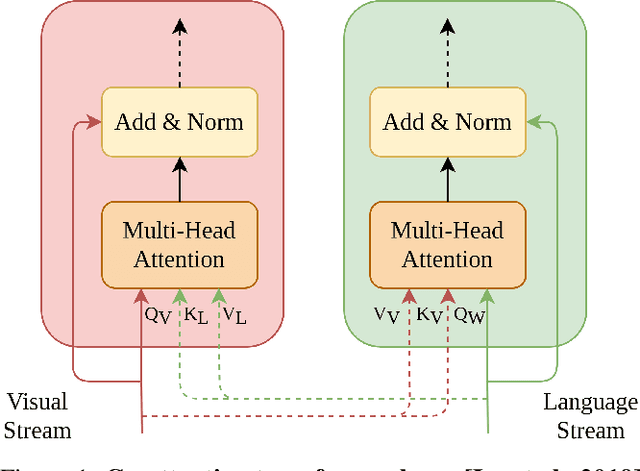

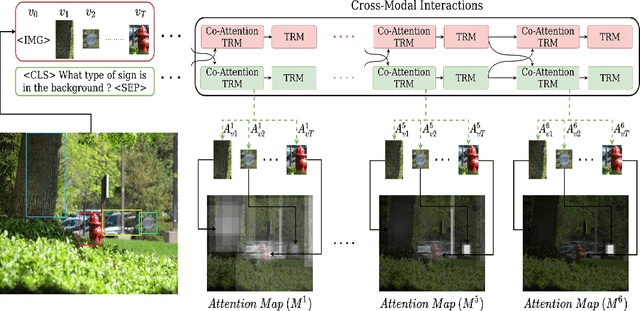

In recent years, multi-modal transformers have shown significant progress in Vision-Language tasks, such as Visual Question Answering (VQA), outperforming previous architectures by a considerable margin. This improvement in VQA is often attributed to the rich interactions between vision and language streams. In this work, we investigate the efficacy of co-attention transformer layers in helping the network focus on relevant regions while answering the question. We generate visual attention maps using the question-conditioned image attention scores in these co-attention layers. We evaluate the effect of the following critical components on visual attention of a state-of-the-art VQA model: (i) number of object region proposals, (ii) question part of speech (POS) tags, (iii) question semantics, (iv) number of co-attention layers, and (v) answer accuracy. We compare the neural network attention maps against human attention maps both qualitatively and quantitatively. Our findings indicate that co-attention transformer modules are crucial in attending to relevant regions of the image given a question. Importantly, we observe that the semantic meaning of the question is not what drives visual attention, but specific keywords in the question do. Our work sheds light on the function and interpretation of co-attention transformer layers, highlights gaps in current networks, and can guide the development of future VQA models and networks that simultaneously process visual and language streams.