 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of the Pooling Methods for Biomedical Relation Extraction with Deep Learning
Paper and Code
Nov 04, 2019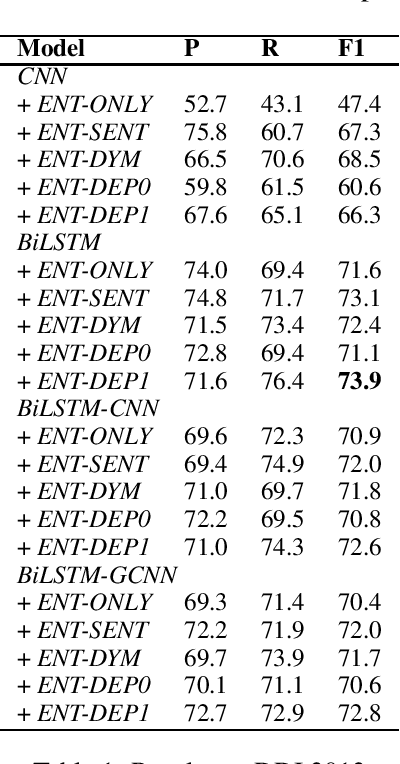
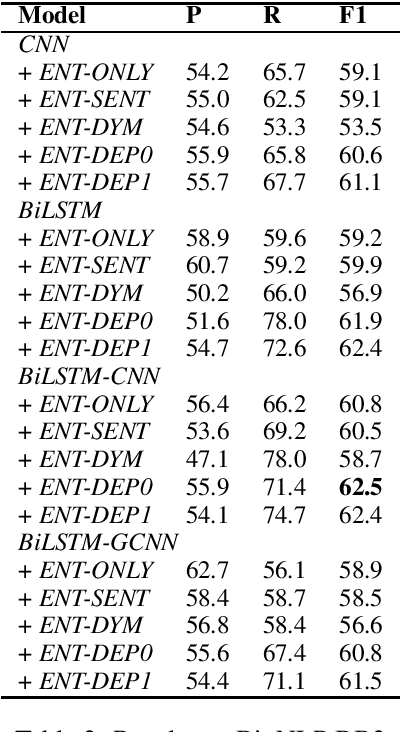
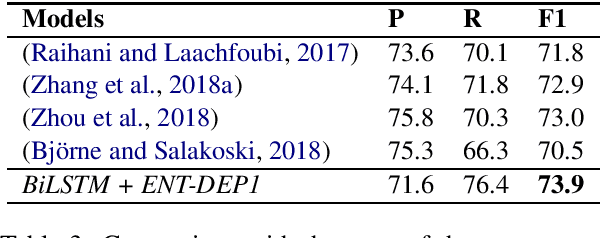
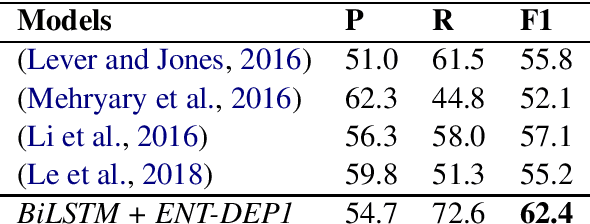
Deep learning models have achieved state-of-the-art performances on many relation extraction datasets. A common element in these deep learning models involves the pooling mechanisms where a sequence of hidden vectors is aggregated to generate a single representation vector, serving as the features to perform prediction for RE. Unfortunately, the models in the literature tend to employ different strategies to perform pooling for RE, leading to the challenge to determine the best pooling mechanism for this problem, especially in the biomedical domain. In order to answer this question, in this work, we conduct a comprehensive study to evaluate the effectiveness of different pooling mechanisms for the deep learning models in biomedical RE. The experimental results suggest that dependency-based pooling is the best pooling strategy for RE in the biomedical domain, yielding the state-of-the-art performance on two benchmark datasets for this problem.