 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Dataset Watermarking in Adversarial Settings
Paper and Code


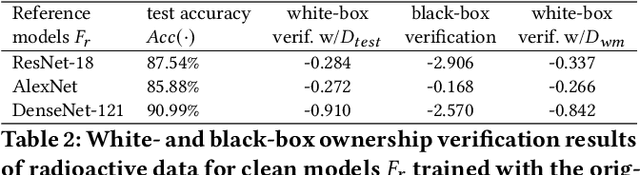

In a data-driven world, datasets constitute a significant economic value. Dataset owners who spend time and money to collect and curate the data are incentivized to ensure that their datasets are not used in ways that they did not authorize. When such misuse occurs, dataset owners need technical mechanisms for demonstrating their ownership of the dataset in question. Dataset watermarking provides one approach for ownership demonstration which can, in turn, deter unauthorized use. In this paper, we investigate a recently proposed data provenance method, radioactive data, to assess if it can be used to demonstrate ownership of (image) datasets used to train machine learning (ML) models. The original paper reported that radioactive data is effective in white-box settings. We show that while this is true for large datasets with many classes, it is not as effective for datasets where the number of classes is low $(\leq 30)$ or the number of samples per class is low $(\leq 500)$. We also show that, counter-intuitively, the black-box verification technique is effective for all datasets used in this paper, even when white-box verification is not. Given this observation, we show that the confidence in white-box verification can be improved by using watermarked samples directly during the verification process. We also highlight the need to assess the robustness of radioactive data if it were to be used for ownership demonstration since it is an adversarial setting unlike provenance identification. Compared to dataset watermarking, ML model watermarking has been explored more extensively in recent literature. However, most of the model watermarking techniques can be defeated via model extraction. We show that radioactive data can effectively survive model extraction attacks, which raises the possibility that it can be used for ML model ownership verification robust against model extraction.