 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the convergence of the Stochastic Heavy Ball Method
Paper and Code
Jun 14, 2020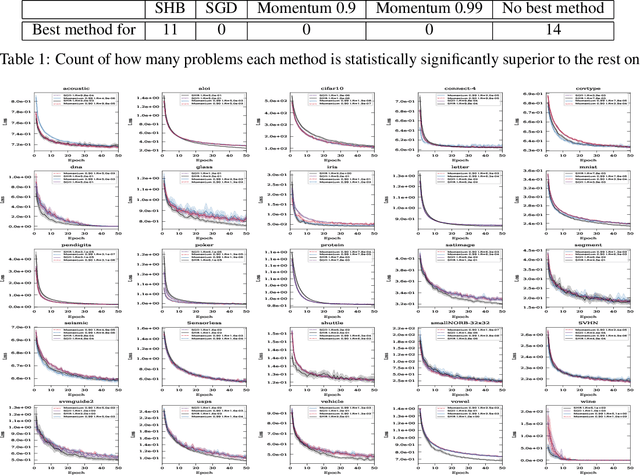
We provide a comprehensive analysis of the Stochastic Heavy Ball (SHB) method (otherwise known as the momentum method), including a convergence of the last iterate of SHB, establishing a faster rate of convergence than existing bounds on the last iterate of Stochastic Gradient Descent (SGD) in the convex setting. Our analysis shows that unlike SGD, no final iterate averaging is necessary with the SHB method. We detail new iteration dependent step sizes (learning rates) and momentum parameters for the SHB that result in this fast convergence. Moreover, assuming only smoothness and convexity, we prove that the iterates of SHB converge \textit{almost surely} to a minimizer, and that the convergence of the function values of (S)HB is asymptotically faster than that of (S)GD in the overparametrized and in the deterministic settings. Our analysis is general, in that it includes all forms of mini-batching and non-uniform samplings as a special case, using an arbitrary sampling framework. Furthermore, our analysis does not rely on the bounded gradient assumptions. Instead, it only relies on smoothness, which is an assumption that can be more readily verified. Finally, we present extensive numerical experiments that show that our theoretically motivated parameter settings give a statistically significant faster convergence across a diverse collection of datasets.