 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of AdaBound and its Connection to SGD
Paper and Code
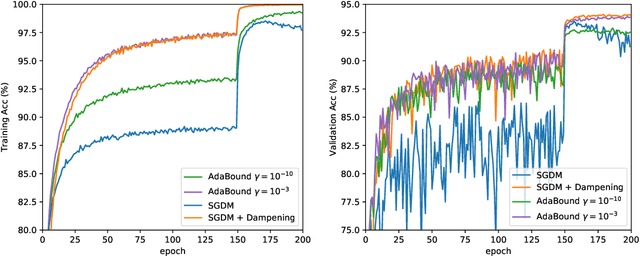
Adaptive gradient methods such as Adam have gained extreme popularity due to their success in training complex neural networks and less sensitivity to hyperparameter tuning compared to SGD. However, it has been recently shown that Adam can fail to converge and might cause poor generalization -- this lead to the design of new, sophisticated adaptive methods which attempt to generalize well while being theoretically reliable. In this technical report we focus on AdaBound, a promising, recently proposed optimizer. We present a stochastic convex problem for which AdaBound can provably take arbitrarily long to converge in terms of a factor which is not accounted for in the convergence rate guarantee of Luo et al. (2019). We present a new $O(\sqrt T)$ regret guarantee under different assumptions on the bound functions, and provide empirical results on CIFAR suggesting that a specific form of momentum SGD can match AdaBound's performance while having less hyperparameters and lower computational costs.