 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Computational Power of Transformers and Its Implications in Sequence Modeling
Paper and Code
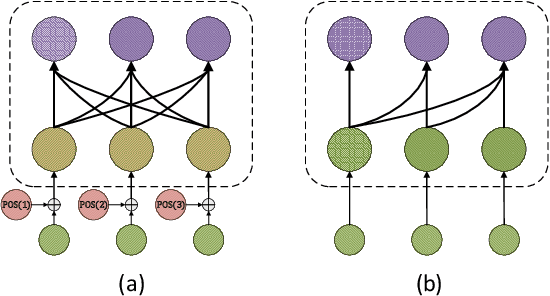

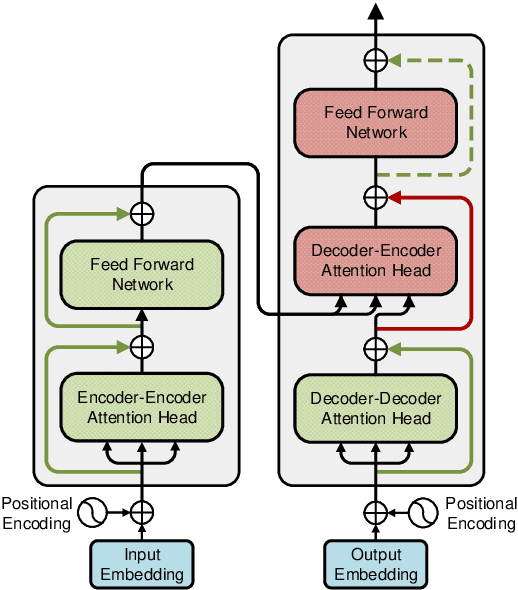
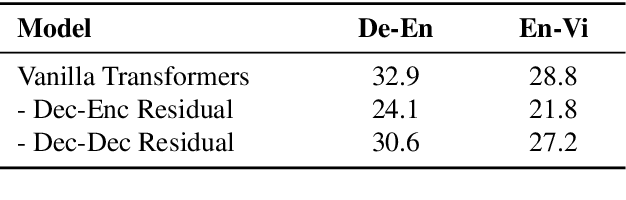
Transformers are being used extensively across several sequence modeling tasks. Significant research effort has been devoted to experimentally probe the inner workings of Transformers. However, our conceptual and theoretical understanding of their power and inherent limitations is still nascent. In particular, the roles of various components in Transformers such as positional encodings, attention heads, residual connections, and feedforward networks, are not clear. In this paper, we take a step towards answering these questions. We analyze the computational power as captured by Turing-completeness. We first provide an alternate proof to show that vanilla Transformers are Turing-complete and then we prove that Transformers with positional masking and without any positional encoding are also Turing-complete. We further analyze the necessity of each component for the Turing-completeness of the network; interestingly, we find that a particular type of residual connection is necessary. We demonstrate the practical implications of our results via experiments on machine translation and synthetic tasks.