 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Composition and Limitations of Publicly Available COVID-19 X-Ray Imaging Datasets
Paper and Code

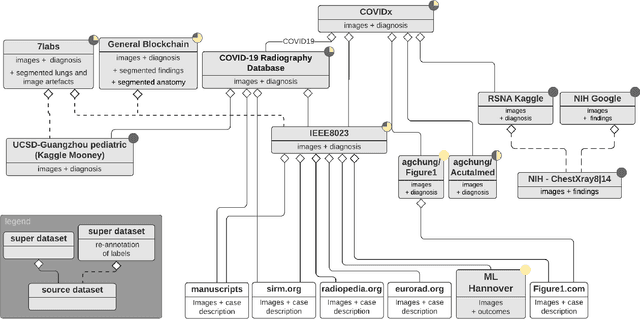
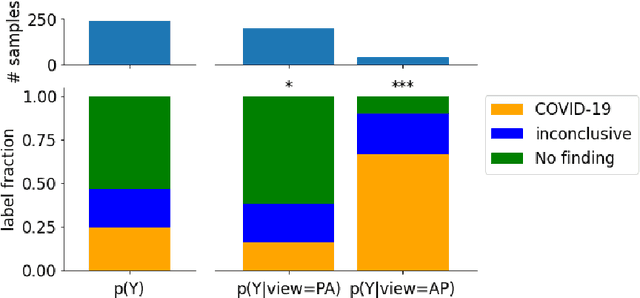
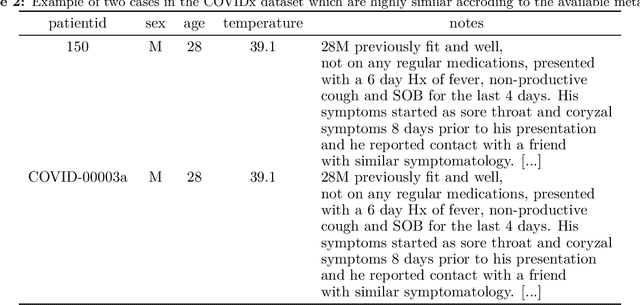
Machine learning based methods for diagnosis and progression prediction of COVID-19 from imaging data have gained significant attention in the last months, in particular by the use of deep learning models. In this context hundreds of models where proposed with the majority of them trained on public datasets. Data scarcity, mismatch between training and target population, group imbalance, and lack of documentation are important sources of bias, hindering the applicability of these models to real-world clinical practice. Considering that datasets are an essential part of model building and evaluation, a deeper understanding of the current landscape is needed. This paper presents an overview of the currently public available COVID-19 chest X-ray datasets. Each dataset is briefly described and potential strength, limitations and interactions between datasets are identified. In particular, some key properties of current datasets that could be potential sources of bias, impairing models trained on them are pointed out. These descriptions are useful for model building on those datasets, to choose the best dataset according the model goal, to take into account the specific limitations to avoid reporting overconfident benchmark results, and to discuss their impact on the generalisation capabilities in a specific clinical setting