 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Bias Against Inductive Biases
Paper and Code
May 28, 2021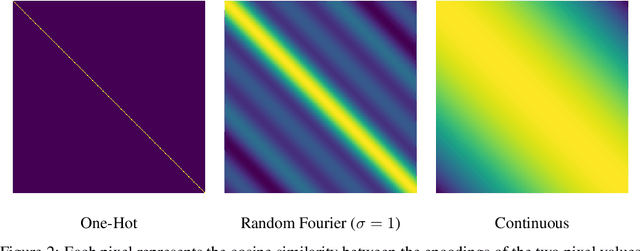
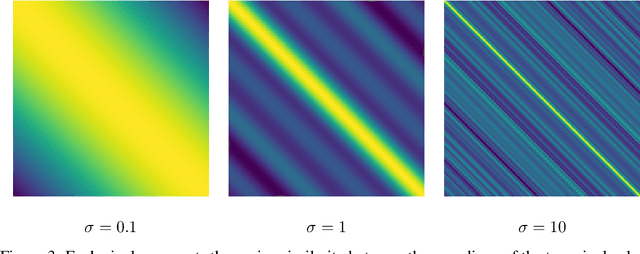
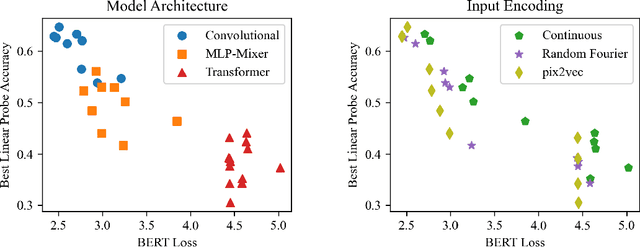
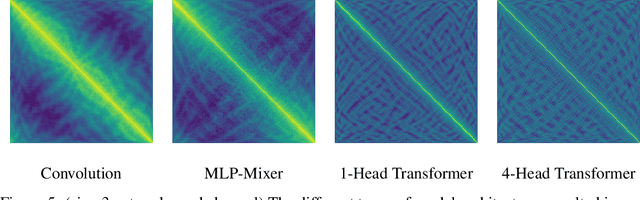
Borrowing from the transformer models that revolutionized the field of natural language processing, self-supervised feature learning for visual tasks has also seen state-of-the-art success using these extremely deep, isotropic networks. However, the typical AI researcher does not have the resources to evaluate, let alone train, a model with several billion parameters and quadratic self-attention activations. To facilitate further research, it is necessary to understand the features of these huge transformer models that can be adequately studied by the typical researcher. One interesting characteristic of these transformer models is that they remove most of the inductive biases present in classical convolutional networks. In this work, we analyze the effect of these and more inductive biases on small to moderately-sized isotropic networks used for unsupervised visual feature learning and show that their removal is not always ideal.