 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Shapley Credit Allocation for Interpretability
Paper and Code
Dec 10, 2020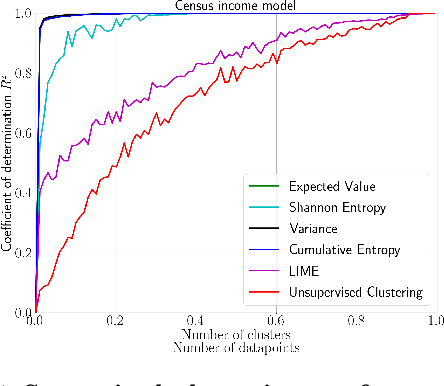
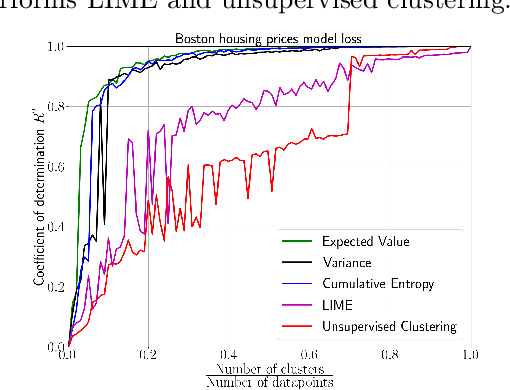

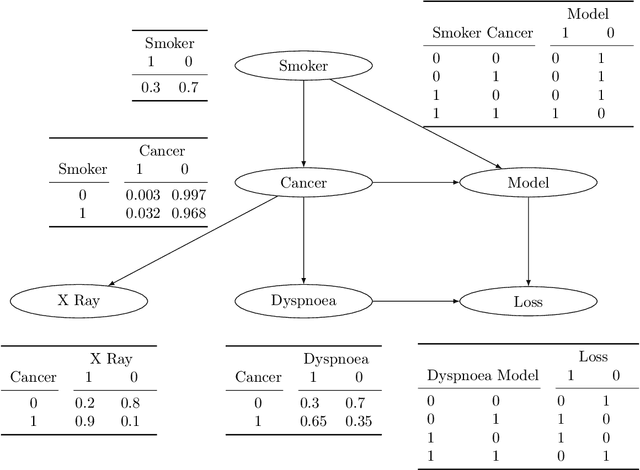
We emphasize the importance of asking the right question when interpreting the decisions of a learning model. We discuss a natural extension of the theoretical machinery from Janzing et. al. 2020, which answers the question "Why did my model predict a person has cancer?" for answering a more involved question, "What caused my model to predict a person has cancer?" While the former quantifies the direct effects of variables on the model, the latter also accounts for indirect effects, thereby providing meaningful insights wherever human beings can reason in terms of cause and effect. We propose three broad categories for interpretations: observational, model-specific and causal each of which are significant in their own right. Furthermore, this paper quantifies feature relevance by weaving different natures of interpretations together with different measures as characteristic functions for Shapley symmetrization. Besides the widely used expected value of the model, we also discuss measures of statistical uncertainty and dispersion as informative candidates, and their merits in generating explanations for each data point, some of which are used in this context for the first time. These measures are not only useful for studying the influence of variables on the model output, but also on the predictive performance of the model, and for that we propose relevant characteristic functions that are also used for the first time.