Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Multi-Agent Deep Deterministic Policy Gradients and their Explainability for SMARTS Environment
Paper and Code
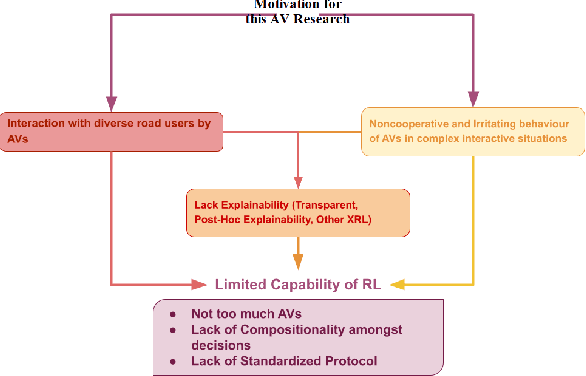
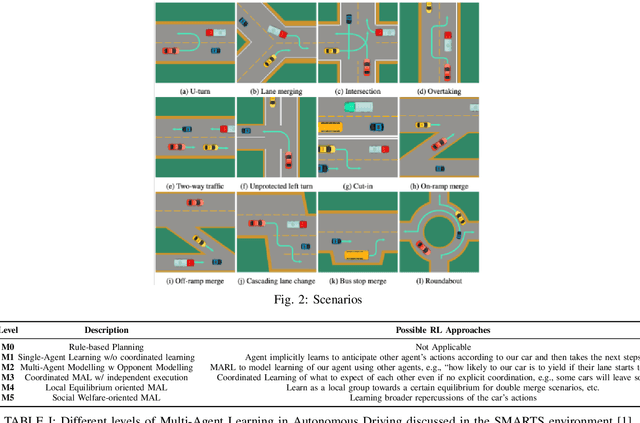
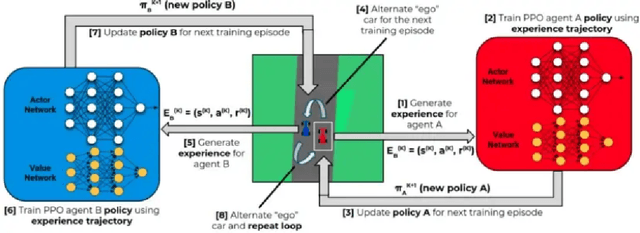
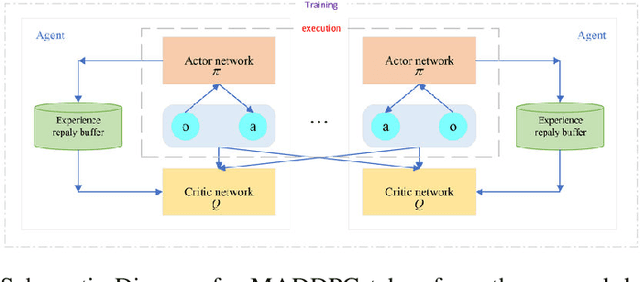
Multi-Agent RL or MARL is one of the complex problems in Autonomous Driving literature that hampers the release of fully-autonomous vehicles today. Several simulators have been in iteration after their inception to mitigate the problem of complex scenarios with multiple agents in Autonomous Driving. One such simulator--SMARTS, discusses the importance of cooperative multi-agent learning. For this problem, we discuss two approaches--MAPPO and MADDPG, which are based on-policy and off-policy RL approaches. We compare our results with the state-of-the-art results for this challenge and discuss the potential areas of improvement while discussing the explainability of these approaches in conjunction with waypoints in the SMARTS environment.
* 6 pages, 5 figures
View paper on