Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Kernel Regression with Data-Dependent Kernels
Paper and Code
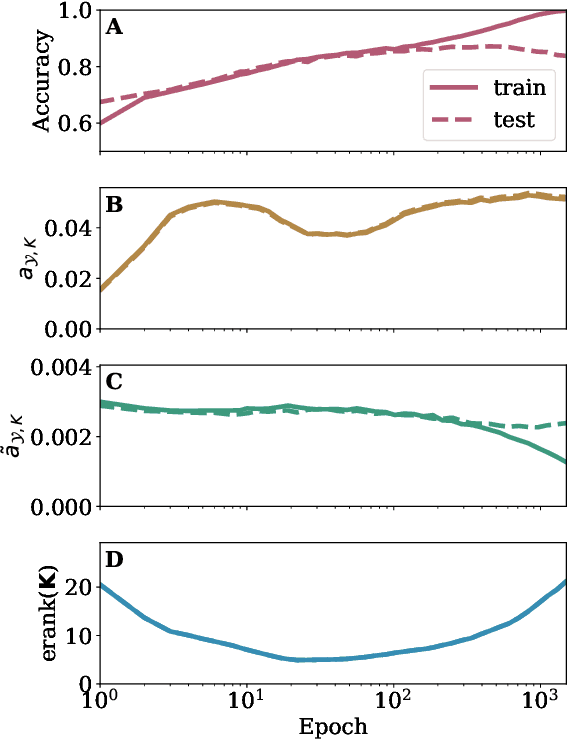
The primary hyperparameter in kernel regression (KR) is the choice of kernel. In most theoretical studies of KR, one assumes the kernel is fixed before seeing the training data. Under this assumption, it is known that the optimal kernel is equal to the prior covariance of the target function. In this note, we consider KR in which the kernel may be updated after seeing the training data. We point out that an analogous choice of kernel using the posterior of the target function is optimal in this setting. Connections to the view of deep neural networks as data-dependent kernel learners are discussed.
* 7 pages, 1 figure
View paper on