 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Feature Learning in Neural Networks with Global Convergence Guarantees
Paper and Code
Apr 22, 2022
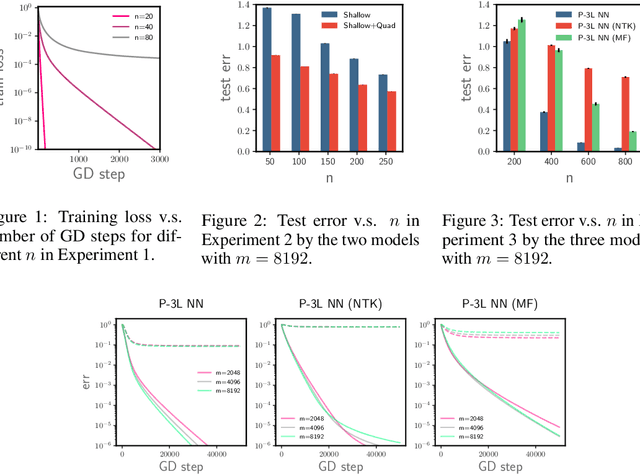
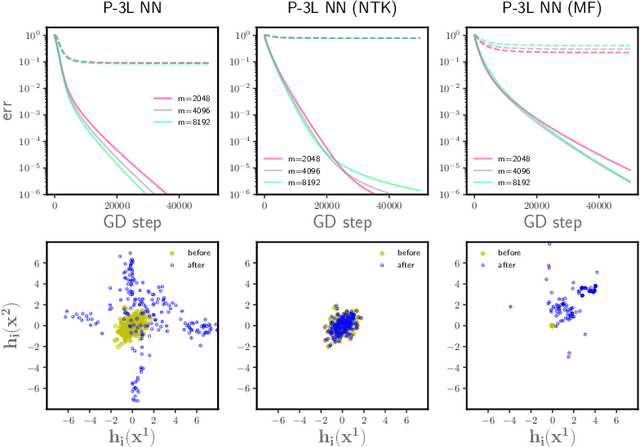
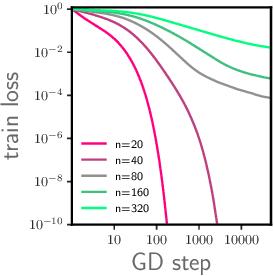
We study the optimization of wide neural networks (NNs) via gradient flow (GF) in setups that allow feature learning while admitting non-asymptotic global convergence guarantees. First, for wide shallow NNs under the mean-field scaling and with a general class of activation functions, we prove that when the input dimension is no less than the size of the training set, the training loss converges to zero at a linear rate under GF. Building upon this analysis, we study a model of wide multi-layer NNs whose second-to-last layer is trained via GF, for which we also prove a linear-rate convergence of the training loss to zero, but regardless of the input dimension. We also show empirically that, unlike in the Neural Tangent Kernel (NTK) regime, our multi-layer model exhibits feature learning and can achieve better generalization performance than its NTK counterpart.