Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Expected Accuracy
Paper and Code
May 01, 2019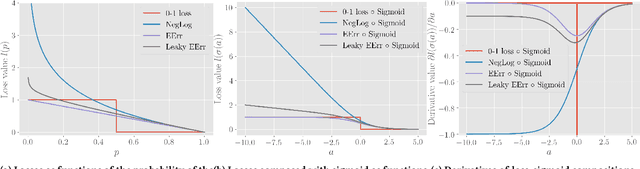
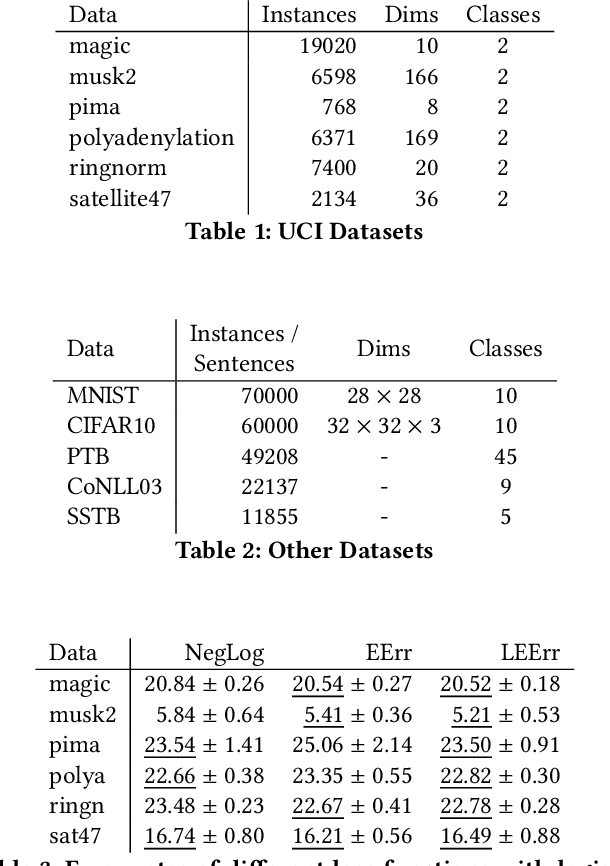
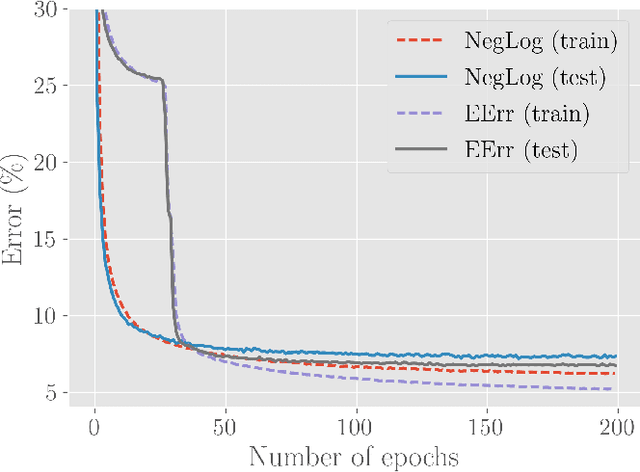
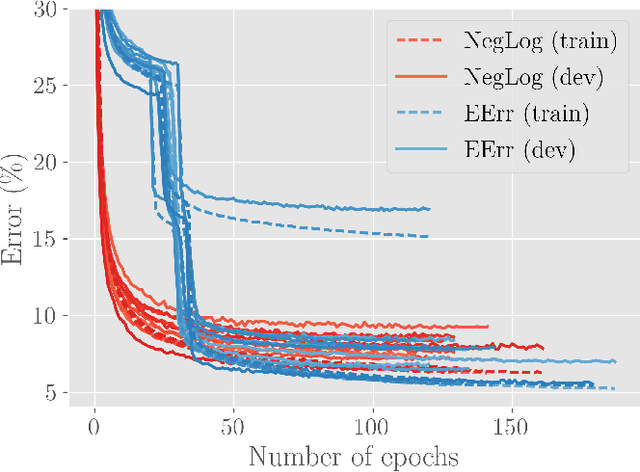
We empirically investigate the (negative) expected accuracy as an alternative loss function to cross entropy (negative log likelihood) for classification tasks. Coupled with softmax activation, it has small derivatives over most of its domain, and is therefore hard to optimize. A modified, leaky version is evaluated on a variety of classification tasks, including digit recognition, image classification, sequence tagging and tree tagging, using a variety of neural architectures such as logistic regression, multilayer perceptron, CNN, LSTM and Tree-LSTM. We show that it yields comparable or better accuracy compared to cross entropy. Furthermore, the proposed objective is shown to be more robust to label noise.
View paper on