 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluating the Generalization of LSTM Models in Formal Languages
Paper and Code

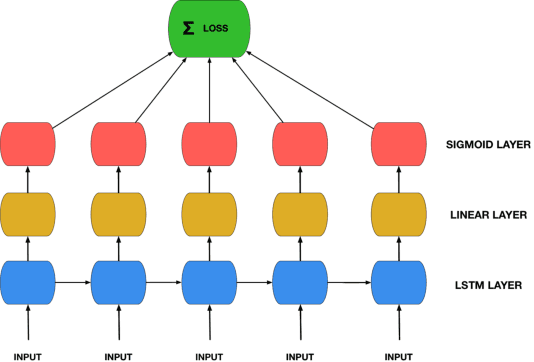

Recurrent Neural Networks (RNNs) are theoretically Turing-complete and established themselves as a dominant model for language processing. Yet, there still remains an uncertainty regarding their language learning capabilities. In this paper, we empirically evaluate the inductive learning capabilities of Long Short-Term Memory networks, a popular extension of simple RNNs, to learn simple formal languages, in particular $a^nb^n$, $a^nb^nc^n$, and $a^nb^nc^nd^n$. We investigate the influence of various aspects of learning, such as training data regimes and model capacity, on the generalization to unobserved samples. We find striking differences in model performances under different training settings and highlight the need for careful analysis and assessment when making claims about the learning capabilities of neural network models.