 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Bayesian Search for the Feasible Space Under Computationally Expensive Constraints
Paper and Code
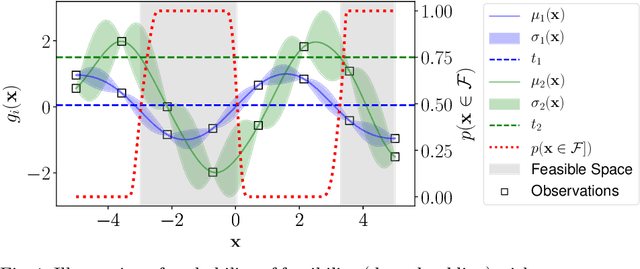
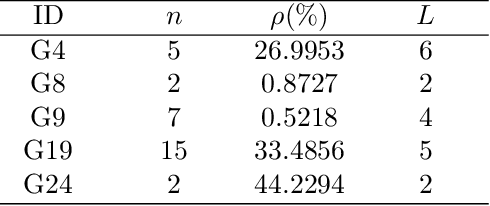

We are often interested in identifying the feasible subset of a decision space under multiple constraints. However, in cases where the constraints cannot be represented by analytical formulae, the cost of solving these problems can be prohibitive, since the only way to determine feasibility is to run computationally or financially expensive simulations. We propose a novel approach for this problem: we learn a surrogate classifier that can rapidly and accurately identify feasible solutions using only a very limited number of samples ($11n$, where $n$ is the dimension of the decision space) obviating the need for full simulations. This is a data-efficient active-learning approach using Gaussian processes (GPs), a form of Bayesian regression models, and we refer to this method as Bayesian search. Using a small training set to begin with, we train a GP model for each constraint. The algorithm then identifies the next decision vector to expensively evaluate using an acquisition function. We subsequently augment the training data set with each newly evaluated solution, improving the accuracy of the estimated feasibility on each step. This iterative process continues until the limit on the number of expensive evaluations is reached. Initially, we adapted acquisition functions from the reliability engineering literature for this purpose. However, these acquisition functions do not appropriately consider the uncertainty in predictions offered by the GP models. We, therefore, introduce a new acquisition function to account for this. The new acquisition function combines the probability that a solution lies at the boundary between feasible and infeasible spaces representing exploitation) as well as the entropy in predictions (representing exploration). In our experiments, the best classifier has a median informedness of at least $97.95\%$ across five of the G problems.