Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn a convergent off -policy temporal difference learning algorithm in on-line learning environment
Paper and Code
May 19, 2016

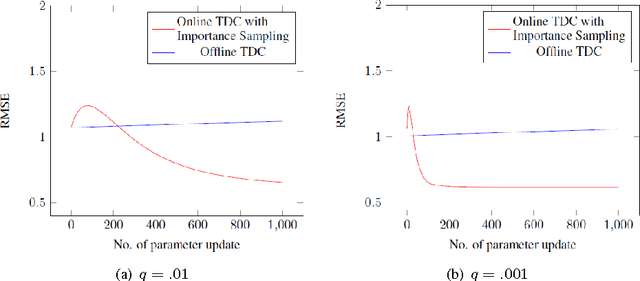

In this paper we provide a rigorous convergence analysis of a "off"-policy temporal difference learning algorithm with linear function approximation and per time-step linear computational complexity in "online" learning environment. The algorithm considered here is TDC with importance weighting introduced by Maei et al. We support our theoretical results by providing suitable empirical results for standard off-policy counterexamples.
* 14 pages. arXiv admin note: text overlap with arXiv:1503.09105
View paper on