 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Deep Reinforcement Learning by Bootstrapping the Covariate Shift
Paper and Code
Jan 27, 2019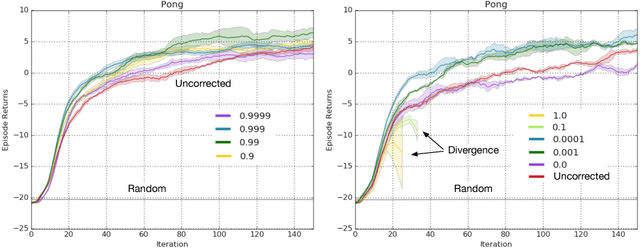


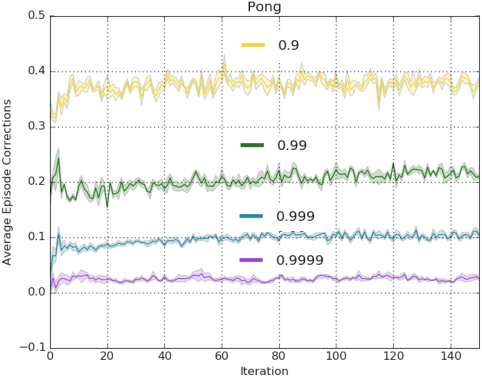
In this paper we revisit the method of off-policy corrections for reinforcement learning (COP-TD) pioneered by Hallak et al. (2017). Under this method, online updates to the value function are reweighted to avoid divergence issues typical of off-policy learning. While Hallak et al.'s solution is appealing, it cannot easily be transferred to nonlinear function approximation. First, it requires a projection step onto the probability simplex; second, even though the operator describing the expected behavior of the off-policy learning algorithm is convergent, it is not known to be a contraction mapping, and hence, may be more unstable in practice. We address these two issues by introducing a discount factor into COP-TD. We analyze the behavior of discounted COP-TD and find it better behaved from a theoretical perspective. We also propose an alternative soft normalization penalty that can be minimized online and obviates the need for an explicit projection step. We complement our analysis with an empirical evaluation of the two techniques in an off-policy setting on the game Pong from the Atari domain where we find discounted COP-TD to be better behaved in practice than the soft normalization penalty. Finally, we perform a more extensive evaluation of discounted COP-TD in 5 games of the Atari domain, where we find performance gains for our approach.