 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR for TIFF Compressed Document Images Directly in Compressed Domain Using Text segmentation and Hidden Markov Model
Paper and Code
Sep 13, 2022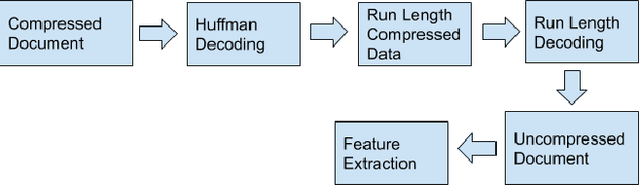



In today's technological era, document images play an important and integral part in our day to day life, and specifically with the surge of Covid-19, digitally scanned documents have become key source of communication, thus avoiding any sort of infection through physical contact. Storage and transmission of scanned document images is a very memory intensive task, hence compression techniques are being used to reduce the image size before archival and transmission. To extract information or to operate on the compressed images, we have two ways of doing it. The first way is to decompress the image and operate on it and subsequently compress it again for the efficiency of storage and transmission. The other way is to use the characteristics of the underlying compression algorithm to directly process the images in their compressed form without involving decompression and re-compression. In this paper, we propose a novel idea of developing an OCR for CCITT (The International Telegraph and Telephone Consultative Committee) compressed machine printed TIFF document images directly in the compressed domain. After segmenting text regions into lines and words, HMM is applied for recognition using three coding modes of CCITT- horizontal, vertical and the pass mode. Experimental results show that OCR on pass modes give a promising results.