 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Using the Car to See the Sidewalk: Quantifying and Controlling the Effects of Context in Classification and Segmentation
Paper and Code
Dec 17, 2018
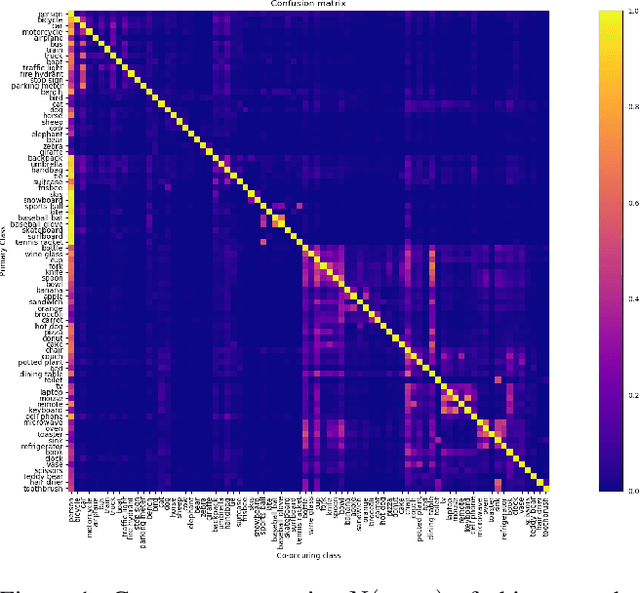

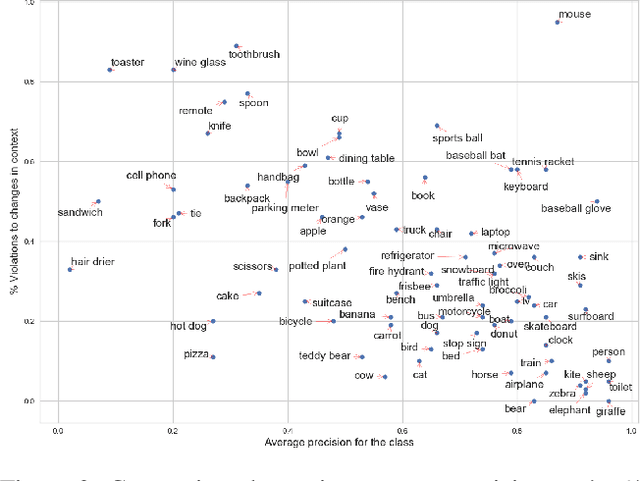
Importance of visual context in scene understanding tasks is well recognized in the computer vision community. However, to what extent the computer vision models for image classification and semantic segmentation are dependent on the context to make their predictions is unclear. A model overly relying on context will fail when encountering objects in context distributions different from training data and hence it is important to identify these dependencies before we can deploy the models in the real-world. We propose a method to quantify the sensitivity of black-box vision models to visual context by editing images to remove selected objects and measuring the response of the target models. We apply this methodology on two tasks, image classification and semantic segmentation, and discover undesirable dependency between objects and context, for example that "sidewalk" segmentation relies heavily on "cars" being present in the image. We propose an object removal based data augmentation solution to mitigate this dependency and increase the robustness of classification and segmentation models to contextual variations. Our experiments show that the proposed data augmentation helps these models improve the performance in out-of-context scenarios, while preserving the performance on regular data.