Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonsmoothness in Machine Learning: specific structure, proximal identification, and applications
Paper and Code
Oct 02, 2020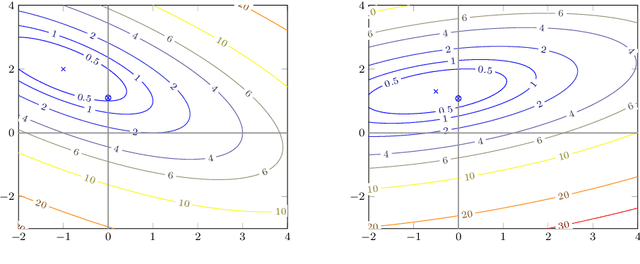
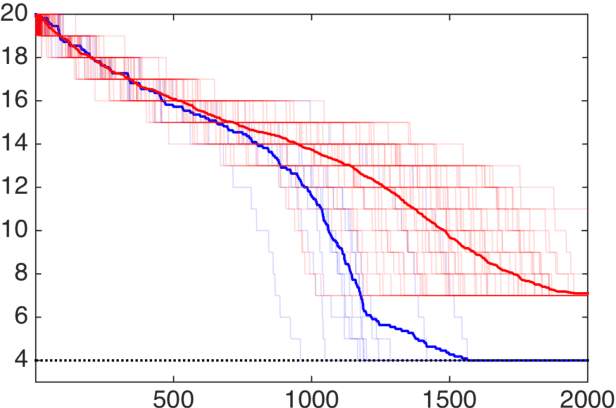
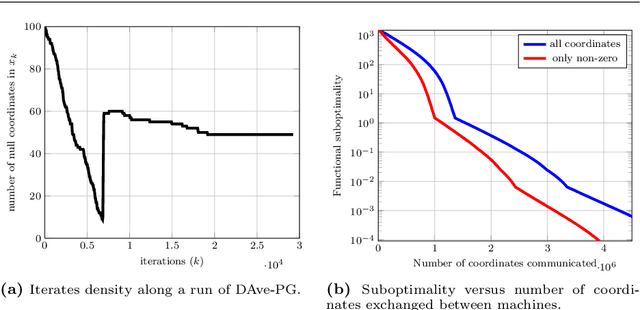
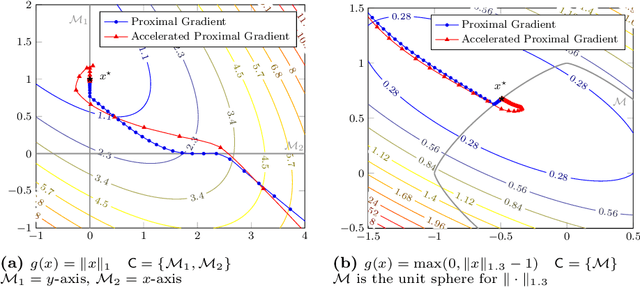
Nonsmoothness is often a curse for optimization; but it is sometimes a blessing, in particular for applications in machine learning. In this paper, we present the specific structure of nonsmooth optimization problems appearing in machine learning and illustrate how to leverage this structure in practice, for compression, acceleration, or dimension reduction. We pay a special attention to the presentation to make it concise and easily accessible, with both simple examples and general results.
* Set-Valued and Variational Analysis, Springer, In press
View paper on