 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Linear Feature Learning in Regression Through Regularisation
Paper and Code

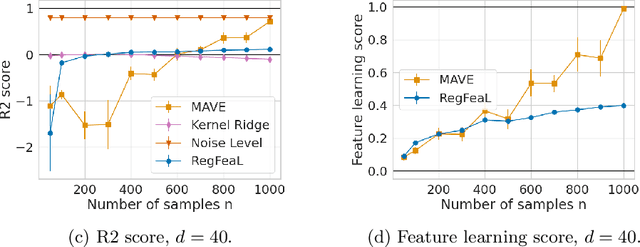


Representation learning plays a crucial role in automated feature selection, particularly in the context of high-dimensional data, where non-parametric methods often struggle. In this study, we focus on supervised learning scenarios where the pertinent information resides within a lower-dimensional linear subspace of the data, namely the multi-index model. If this subspace were known, it would greatly enhance prediction, computation, and interpretation. To address this challenge, we propose a novel method for linear feature learning with non-parametric prediction, which simultaneously estimates the prediction function and the linear subspace. Our approach employs empirical risk minimisation, augmented with a penalty on function derivatives, ensuring versatility. Leveraging the orthogonality and rotation invariance properties of Hermite polynomials, we introduce our estimator, named RegFeaL. By utilising alternative minimisation, we iteratively rotate the data to improve alignment with leading directions and accurately estimate the relevant dimension in practical settings. We establish that our method yields a consistent estimator of the prediction function with explicit rates. Additionally, we provide empirical results demonstrating the performance of RegFeaL in various experiments.