 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parallel Voice Conversion with Augmented Classifier Star Generative Adversarial Networks
Paper and Code
Sep 11, 2020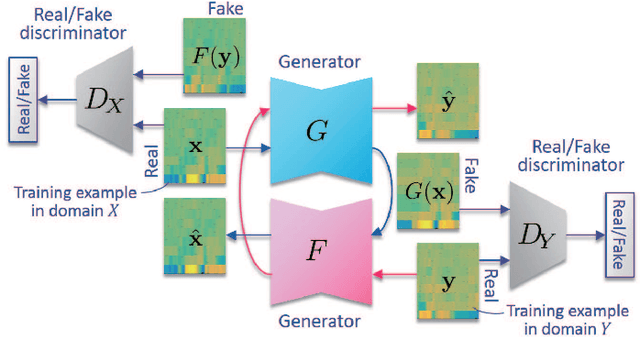
We previously proposed a method that allows for non-parallel voice conversion (VC) by using a variant of generative adversarial networks (GANs) called StarGAN. The main features of our method, called StarGAN-VC, are as follows: First, it requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training. Second, it can simultaneously learn mappings across multiple domains using a single generator network so that it can fully exploit available training data collected from multiple domains to capture latent features that are common to all the domains. Third, it is able to generate converted speech signals quickly enough to allow real-time implementations and requires only several minutes of training examples to generate reasonably realistic-sounding speech. In this paper, we describe three formulations of StarGAN, including a newly introduced novel StarGAN variant called "Augmented classifier StarGAN (A-StarGAN)", and compare them in a non-parallel VC task. We also compare them with several baseline methods.