 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Myopic Multifidelity Bayesian Optimization
Paper and Code
Jul 19, 2022
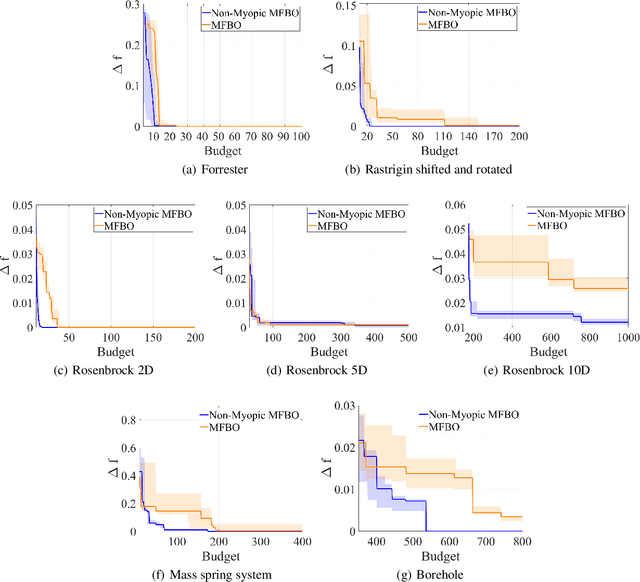
Bayesian optimization is a popular framework for the optimization of black box functions. Multifidelity methods allows to accelerate Bayesian optimization by exploiting low-fidelity representations of expensive objective functions. Popular multifidelity Bayesian strategies rely on sampling policies that account for the immediate reward obtained evaluating the objective function at a specific input, precluding greater informative gains that might be obtained looking ahead more steps. This paper proposes a non-myopic multifidelity Bayesian framework to grasp the long-term reward from future steps of the optimization. Our computational strategy comes with a two-step lookahead multifidelity acquisition function that maximizes the cumulative reward obtained measuring the improvement in the solution over two steps ahead. We demonstrate that the proposed algorithm outperforms a standard multifidelity Bayesian framework on popular benchmark optimization problems.