 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Deterministic Policies in Markovian Decision Processes
Paper and Code
Jan 16, 2014
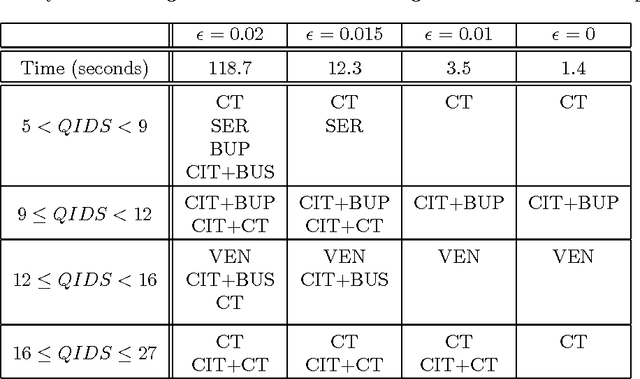
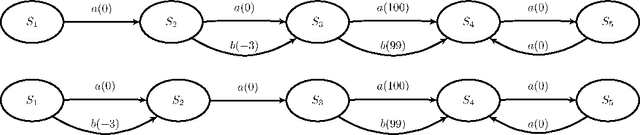
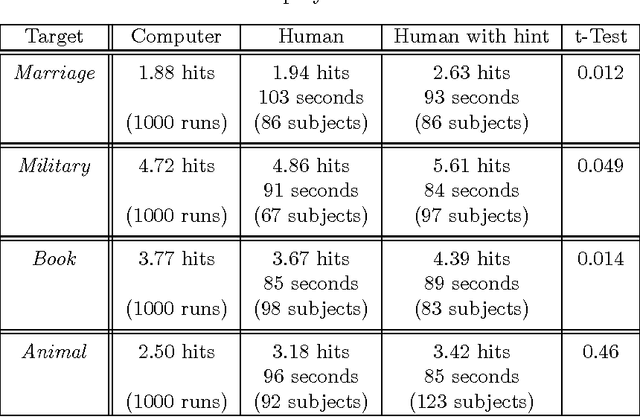
Markovian processes have long been used to model stochastic environments. Reinforcement learning has emerged as a framework to solve sequential planning and decision-making problems in such environments. In recent years, attempts were made to apply methods from reinforcement learning to construct decision support systems for action selection in Markovian environments. Although conventional methods in reinforcement learning have proved to be useful in problems concerning sequential decision-making, they cannot be applied in their current form to decision support systems, such as those in medical domains, as they suggest policies that are often highly prescriptive and leave little room for the users input. Without the ability to provide flexible guidelines, it is unlikely that these methods can gain ground with users of such systems. This paper introduces the new concept of non-deterministic policies to allow more flexibility in the users decision-making process, while constraining decisions to remain near optimal solutions. We provide two algorithms to compute non-deterministic policies in discrete domains. We study the output and running time of these method on a set of synthetic and real-world problems. In an experiment with human subjects, we show that humans assisted by hints based on non-deterministic policies outperform both human-only and computer-only agents in a web navigation task.