 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-asymptotic and Accurate Learning of Nonlinear Dynamical Systems
Paper and Code
Feb 20, 2020

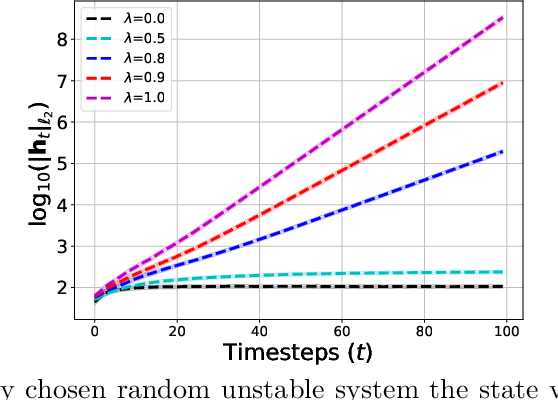
We consider the problem of learning stabilizable systems governed by nonlinear state equation $h_{t+1}=\phi(h_t,u_t;\theta)+w_t$. Here $\theta$ is the unknown system dynamics, $h_t $ is the state, $u_t$ is the input and $w_t$ is the additive noise vector. We study gradient based algorithms to learn the system dynamics $\theta$ from samples obtained from a single finite trajectory. If the system is run by a stabilizing input policy, we show that temporally-dependent samples can be approximated by i.i.d. samples via a truncation argument by using mixing-time arguments. We then develop new guarantees for the uniform convergence of the gradients of empirical loss. Unlike existing work, our bounds are noise sensitive which allows for learning ground-truth dynamics with high accuracy and small sample complexity. Together, our results facilitate efficient learning of the general nonlinear system under stabilizing policy. We specialize our guarantees to entry-wise nonlinear activations and verify our theory in various numerical experiments