 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Tolerant Unsupervised Adapter for Vision-Language Models
Paper and Code
Sep 26, 2023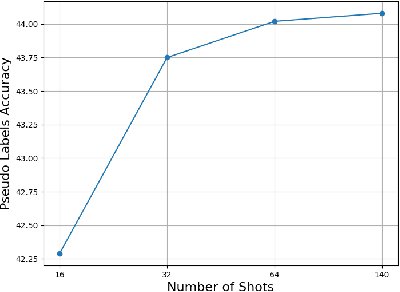
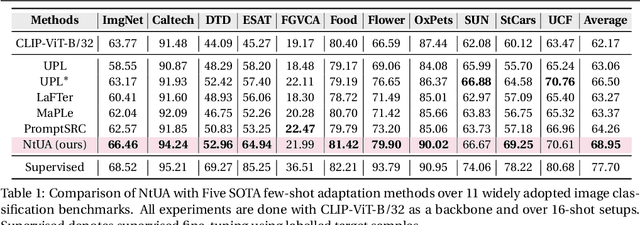
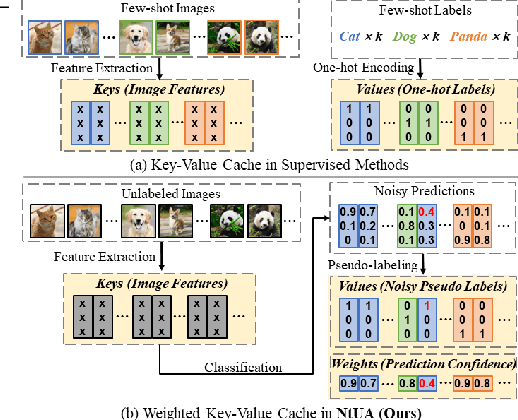
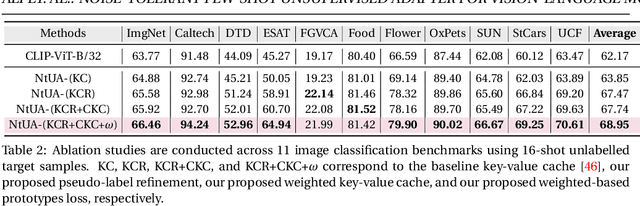
Recent advances in large-scale vision-language models have achieved very impressive performance in various zero-shot image classification tasks. While prior studies have demonstrated significant improvements by introducing few-shot labelled target samples, they still require labelling of target samples, which greatly degrades their scalability while handling various visual recognition tasks. We design NtUA, a Noise-tolerant Unsupervised Adapter that allows learning superior target models with few-shot unlabelled target samples. NtUA works as a key-value cache that formulates visual features and predicted pseudo-labels of the few-shot unlabelled target samples as key-value pairs. It consists of two complementary designs. The first is adaptive cache formation that combats pseudo-label noises by weighting the key-value pairs according to their prediction confidence. The second is pseudo-label rectification, which corrects both pair values (i.e., pseudo-labels) and cache weights by leveraging knowledge distillation from large-scale vision language models. Extensive experiments show that NtUA achieves superior performance consistently across multiple widely adopted benchmarks.