 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise is All You Need: Private Second-Order Convergence of Noisy SGD
Paper and Code
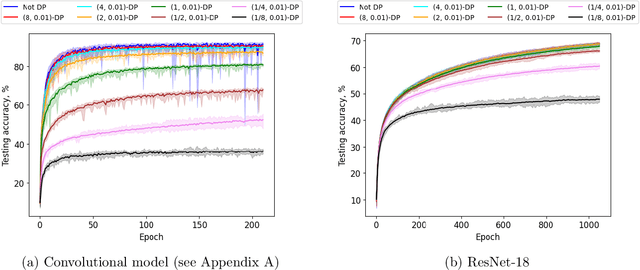
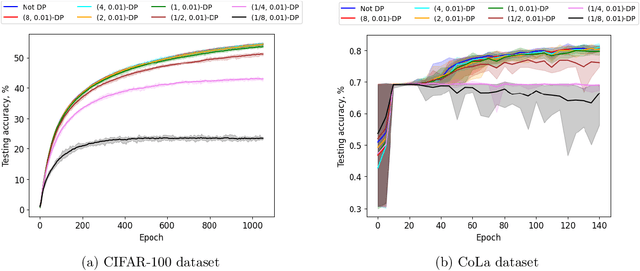
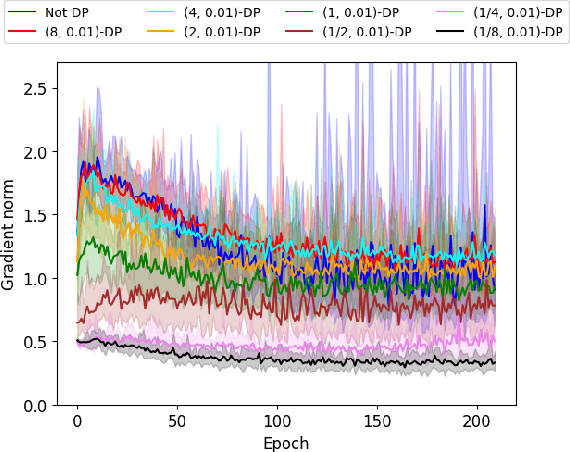
Private optimization is a topic of major interest in machine learning, with differentially private stochastic gradient descent (DP-SGD) playing a key role in both theory and practice. Furthermore, DP-SGD is known to be a powerful tool in contexts beyond privacy, including robustness, machine unlearning, etc. Existing analyses of DP-SGD either make relatively strong assumptions (e.g., Lipschitz continuity of the loss function, or even convexity) or prove only first-order convergence (and thus might end at a saddle point in the non-convex setting). At the same time, there has been progress in proving second-order convergence of the non-private version of ``noisy SGD'', as well as progress in designing algorithms that are more complex than DP-SGD and do guarantee second-order convergence. We revisit DP-SGD and show that ``noise is all you need'': the noise necessary for privacy already implies second-order convergence under the standard smoothness assumptions, even for non-Lipschitz loss functions. Hence, we get second-order convergence essentially for free: DP-SGD, the workhorse of modern private optimization, under minimal assumptions can be used to find a second-order stationary point.