 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise can be helpful for variational quantum algorithms
Paper and Code
Oct 13, 2022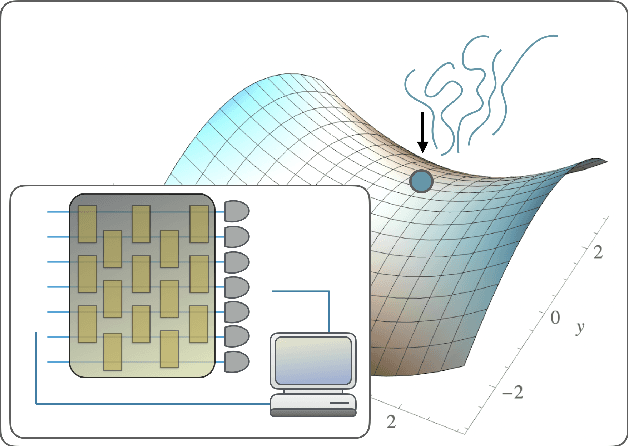
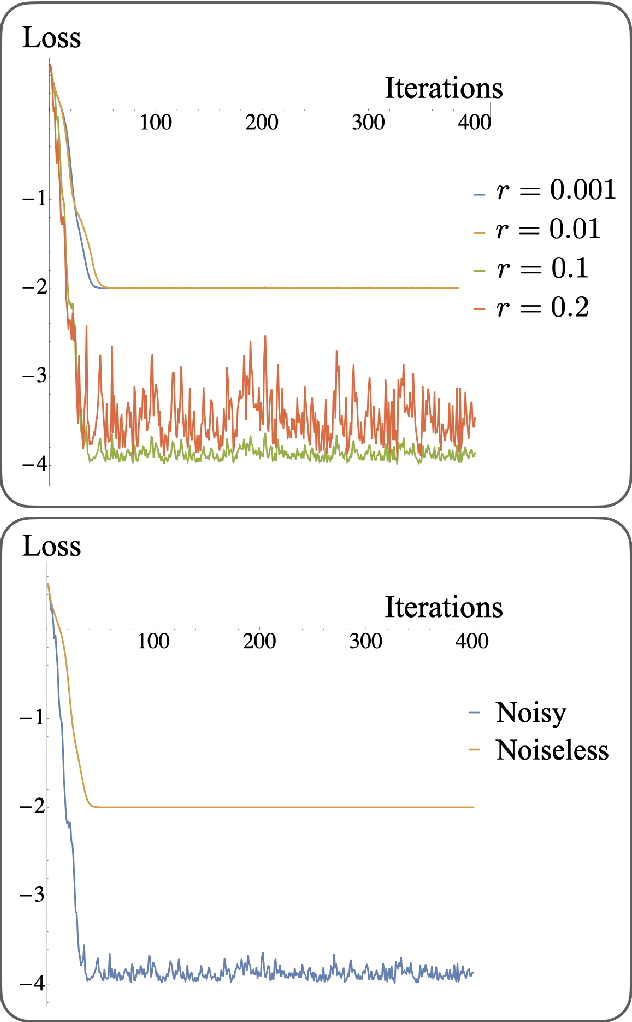
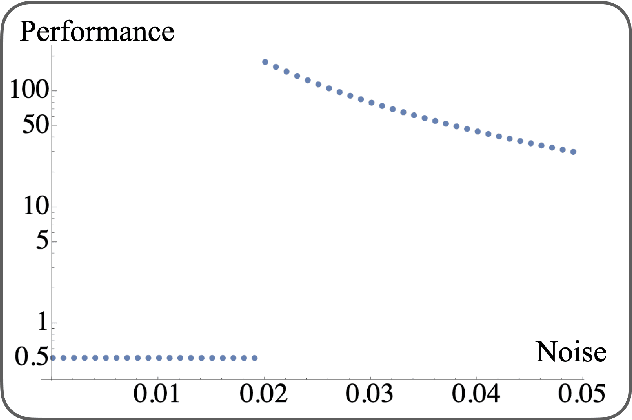
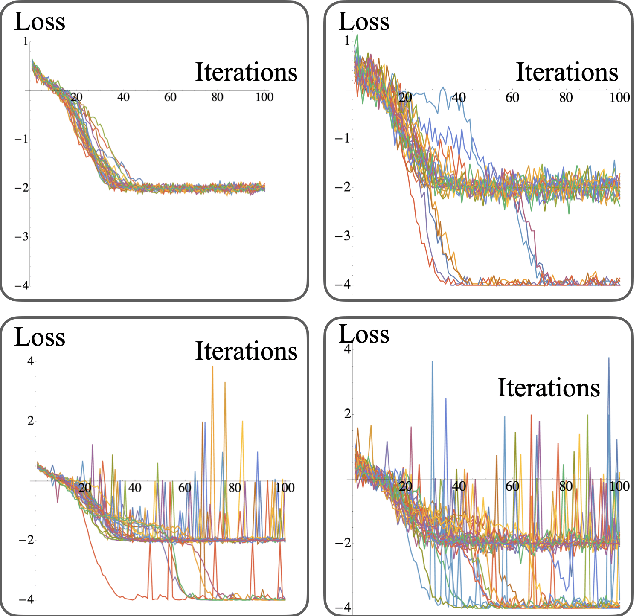
Saddle points constitute a crucial challenge for first-order gradient descent algorithms. In notions of classical machine learning, they are avoided for example by means of stochastic gradient descent methods. In this work, we provide evidence that the saddle points problem can be naturally avoided in variational quantum algorithms by exploiting the presence of stochasticity. We prove convergence guarantees of the approach and its practical functioning at hand of examples. We argue that the natural stochasticity of variational algorithms can be beneficial for avoiding strict saddle points, i.e., those saddle points with at least one negative Hessian eigenvalue. This insight that some noise levels could help in this perspective is expected to add a new perspective to notions of near-term variational quantum algorithms.