 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Laundering: Removing Black-Box Backdoor Watermarks from Deep Neural Networks
Paper and Code



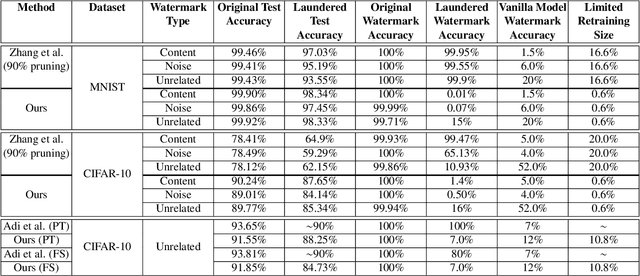
Creating a state-of-the-art deep-learning system requires vast amounts of data, expertise, and hardware, yet research into embedding copyright protection for neural networks has been limited. One of the main methods for achieving such protection involves relying on the susceptibility of neural networks to backdoor attacks, but the robustness of these tactics has been primarily evaluated against pruning, fine-tuning, and model inversion attacks. In this work, we propose a neural network "laundering" algorithm to remove black-box backdoor watermarks from neural networks even when the adversary has no prior knowledge of the structure of the watermark. We are able to effectively remove watermarks used for recent defense or copyright protection mechanisms while achieving test accuracies above 97% and 80% for both MNIST and CIFAR-10, respectively. For all backdoor watermarking methods addressed in this paper, we find that the robustness of the watermark is significantly weaker than the original claims. We also demonstrate the feasibility of our algorithm in more complex tasks as well as in more realistic scenarios where the adversary is able to carry out efficient laundering attacks using less than 1% of the original training set size, demonstrating that existing backdoor watermarks are not sufficient to reach their claims.