 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Granular Sound Synthesis
Paper and Code
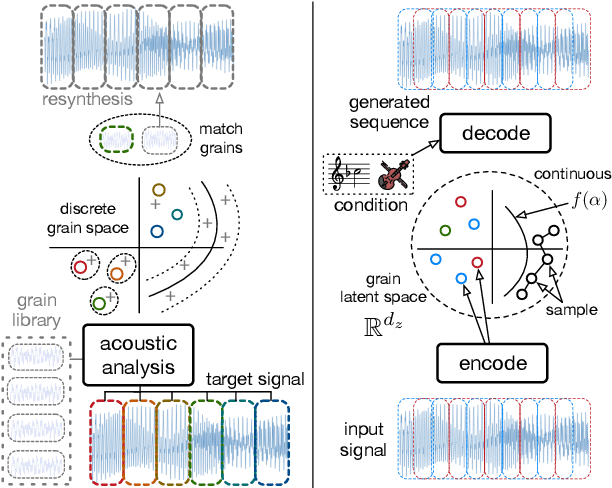
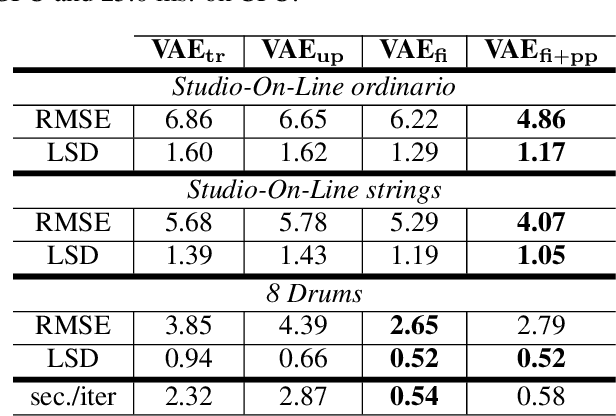
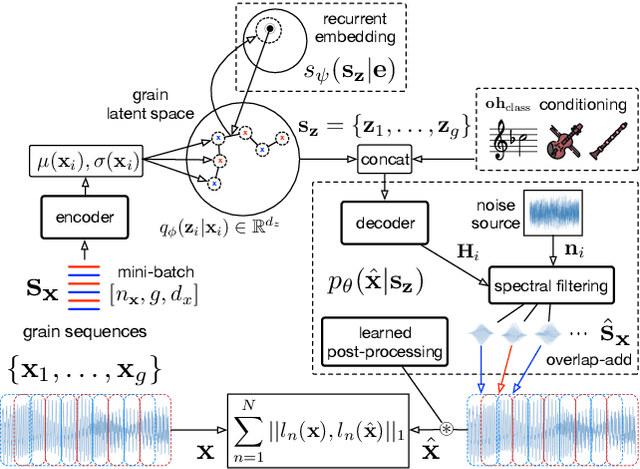
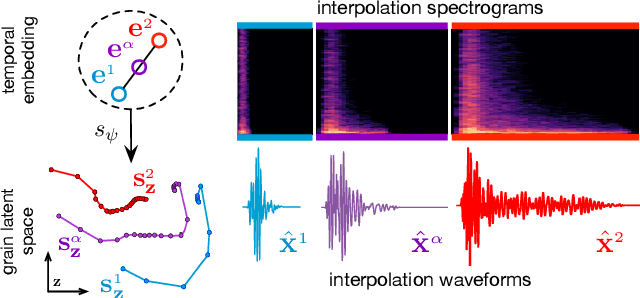
Granular sound synthesis is a popular audio generation technique based on rearranging sequences of small waveform windows. In order to control the synthesis, all grains in a given corpus are analyzed through a set of acoustic descriptors. This provides a representation reflecting some form of local similarities across the grains. However, the quality of this grain space is bound by that of the descriptors. Its traversal is not continuously invertible to signal and does not render any structured temporality. We demonstrate that generative neural networks can implement granular synthesis while alleviating most of its shortcomings. We efficiently replace its audio descriptor basis by a probabilistic latent space learned with a Variational Auto-Encoder. A major advantage of our proposal is that the resulting grain space is invertible, meaning that we can continuously synthesize sound when traversing its dimensions. It also implies that original grains are not stored for synthesis. To learn structured paths inside this latent space, we add a higher-level temporal embedding trained on arranged grain sequences. The model can be applied to many types of libraries, including pitched notes or unpitched drums and environmental noises. We experiment with the common granular synthesis processes and enable new ones.