 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Characteristic Activation Value Analysis for Improved ReLU Network Feature Learning
Paper and Code
May 25, 2023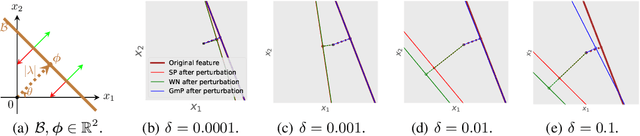

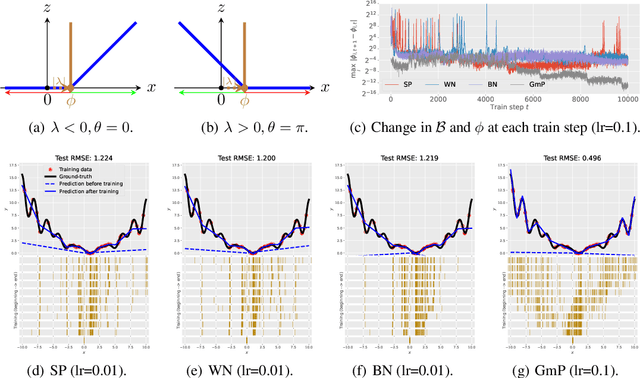
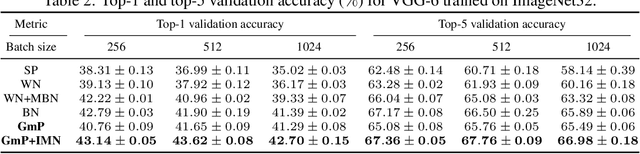
We examine the characteristic activation values of individual ReLU units in neural networks. We refer to the corresponding set for such characteristic activation values in the input space as the characteristic activation set of a ReLU unit. We draw an explicit connection between the characteristic activation set and learned features in ReLU networks. This connection leads to new insights into why various neural network normalization techniques used in modern deep learning architectures regularize and stabilize SGD optimization. Utilizing these insights, we propose a geometric approach to parameterize ReLU networks for improved feature learning. We empirically verify its usefulness with less carefully chosen initialization schemes and larger learning rates. We report improved optimization stability, faster convergence speed, and better generalization performance.