 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly-Tight and Oblivious Algorithms for Explainable Clustering
Paper and Code
Jun 30, 2021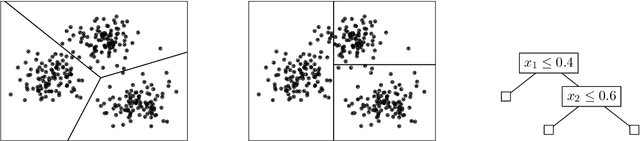

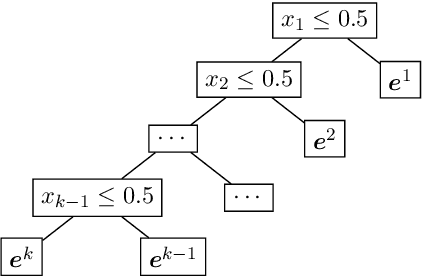
We study the problem of explainable clustering in the setting first formalized by Moshkovitz, Dasgupta, Rashtchian, and Frost (ICML 2020). A $k$-clustering is said to be explainable if it is given by a decision tree where each internal node splits data points with a threshold cut in a single dimension (feature), and each of the $k$ leaves corresponds to a cluster. We give an algorithm that outputs an explainable clustering that loses at most a factor of $O(\log^2 k)$ compared to an optimal (not necessarily explainable) clustering for the $k$-medians objective, and a factor of $O(k \log^2 k)$ for the $k$-means objective. This improves over the previous best upper bounds of $O(k)$ and $O(k^2)$, respectively, and nearly matches the previous $\Omega(\log k)$ lower bound for $k$-medians and our new $\Omega(k)$ lower bound for $k$-means. The algorithm is remarkably simple. In particular, given an initial not necessarily explainable clustering in $\mathbb{R}^d$, it is oblivious to the data points and runs in time $O(dk \log^2 k)$, independent of the number of data points $n$. Our upper and lower bounds also generalize to objectives given by higher $\ell_p$-norms.