 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Explainable $k$-Means for All Dimensions
Paper and Code
Jun 29, 2021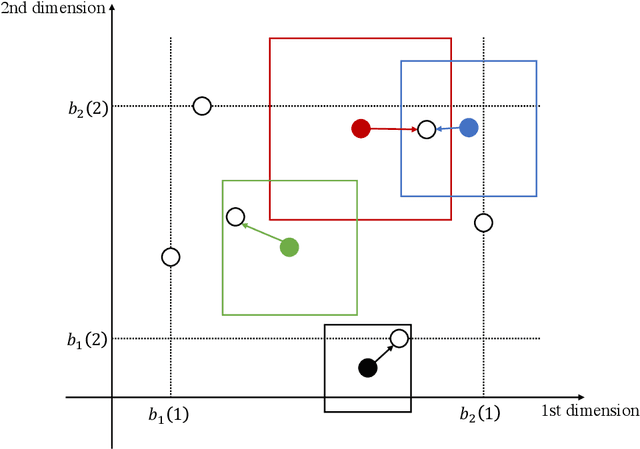
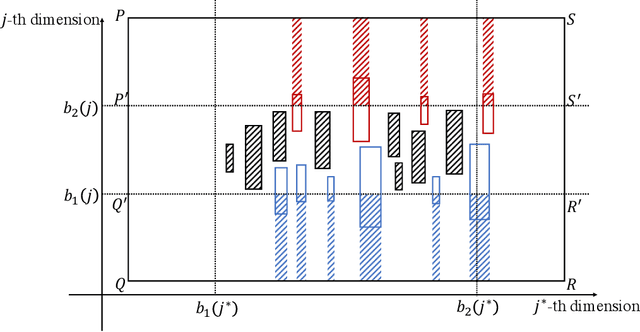
Many clustering algorithms are guided by certain cost functions such as the widely-used $k$-means cost. These algorithms divide data points into clusters with often complicated boundaries, creating difficulties in explaining the clustering decision. In a recent work, Dasgupta, Frost, Moshkovitz, and Rashtchian (ICML'20) introduced explainable clustering, where the cluster boundaries are axis-parallel hyperplanes and the clustering is obtained by applying a decision tree to the data. The central question here is: how much does the explainability constraint increase the value of the cost function? Given $d$-dimensional data points, we show an efficient algorithm that finds an explainable clustering whose $k$-means cost is at most $k^{1 - 2/d}\mathrm{poly}(d\log k)$ times the minimum cost achievable by a clustering without the explainability constraint, assuming $k,d\ge 2$. Combining this with an independent work by Makarychev and Shan (ICML'21), we get an improved bound of $k^{1 - 2/d}\mathrm{polylog}(k)$, which we show is optimal for every choice of $k,d\ge 2$ up to a poly-logarithmic factor in $k$. For $d = 2$ in particular, we show an $O(\log k\log\log k)$ bound, improving exponentially over the previous best bound of $\widetilde O(k)$.