 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Algorithms for Autonomous Exploration and Multi-Goal Stochastic Shortest Path
Paper and Code
May 22, 2022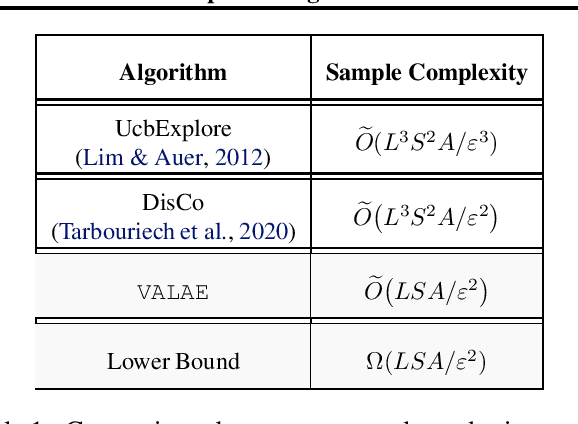
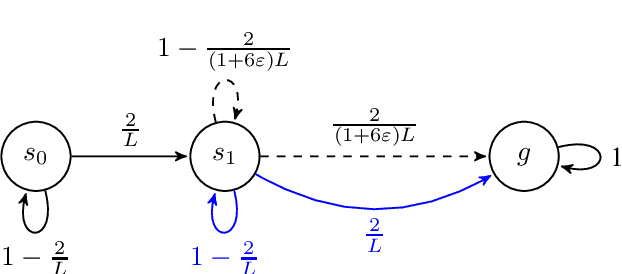
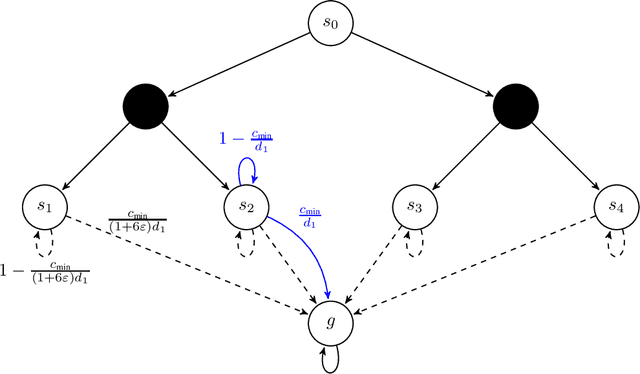
We revisit the incremental autonomous exploration problem proposed by Lim & Auer (2012). In this setting, the agent aims to learn a set of near-optimal goal-conditioned policies to reach the $L$-controllable states: states that are incrementally reachable from an initial state $s_0$ within $L$ steps in expectation. We introduce a new algorithm with stronger sample complexity bounds than existing ones. Furthermore, we also prove the first lower bound for the autonomous exploration problem. In particular, the lower bound implies that our proposed algorithm, Value-Aware Autonomous Exploration, is nearly minimax-optimal when the number of $L$-controllable states grows polynomially with respect to $L$. Key in our algorithm design is a connection between autonomous exploration and multi-goal stochastic shortest path, a new problem that naturally generalizes the classical stochastic shortest path problem. This new problem and its connection to autonomous exploration can be of independent interest.