 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Chinese Reader: A Dataset Towards Native-Level Chinese Machine Reading Comprehension
Paper and Code
Dec 14, 2021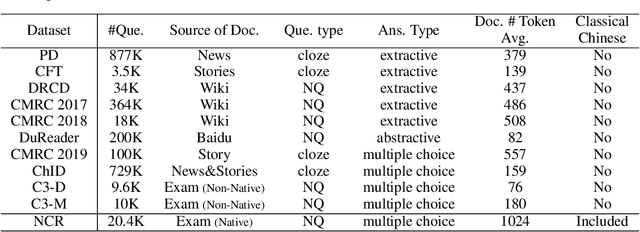
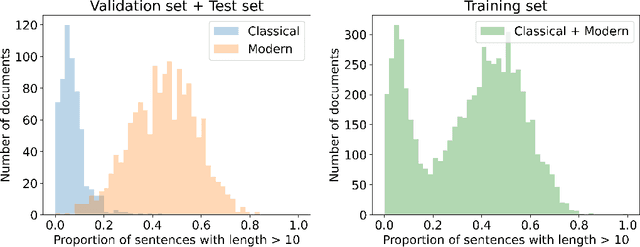
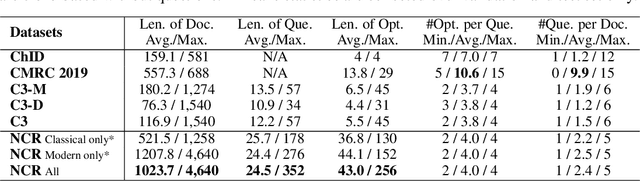

We present Native Chinese Reader (NCR), a new machine reading comprehension (MRC) dataset with particularly long articles in both modern and classical Chinese. NCR is collected from the exam questions for the Chinese course in China's high schools, which are designed to evaluate the language proficiency of native Chinese youth. Existing Chinese MRC datasets are either domain-specific or focusing on short contexts of a few hundreds of characters in modern Chinese only. By contrast, NCR contains 8390 documents with an average length of 1024 characters covering a wide range of Chinese writing styles, including modern articles, classical literature and classical poetry. A total of 20477 questions on these documents also require strong reasoning abilities and common sense to figure out the correct answers. We implemented multiple baseline models using popular Chinese pre-trained models and additionally launched an online competition using our dataset to examine the limit of current methods. The best model achieves 59% test accuracy while human evaluation shows an average accuracy of 79%, which indicates a significant performance gap between current MRC models and native Chinese speakers. We release the dataset at https://sites.google.com/view/native-chinese-reader/.