 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition for Audio De-Identification
Paper and Code
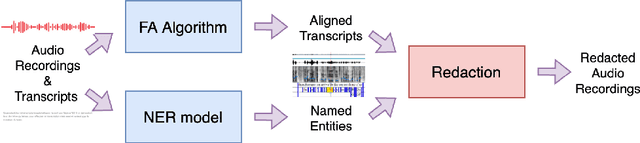

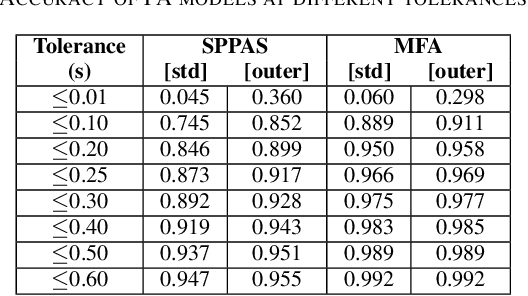
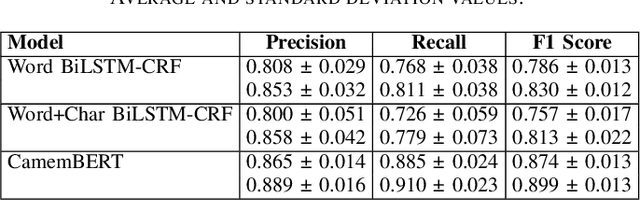
Data anonymization is often a task carried out by humans. Automating it would reduce the cost and time required to complete this task. This paper presents a pipeline to automate the anonymization of audio data in French. We propose a pipeline, which takes audio files with their transcriptions and removes the named entities (NEs) present in the audio. Our pipeline is made up of a forced aligner, which aligns words in an audio transcript with speech and a model that performs named entity recognition (NER). Then, the audio segments that correspond to NEs are substituted with silence to anonymize audio. We compared forced aligners and NER models to find the best ones for our scenario. We evaluated our pipeline on a small hand-annotated dataset, achieving an F1 score of 0.769. This result shows that automating this task is feasible.