 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Scaling and Expressive Power of Sequence Models
Paper and Code


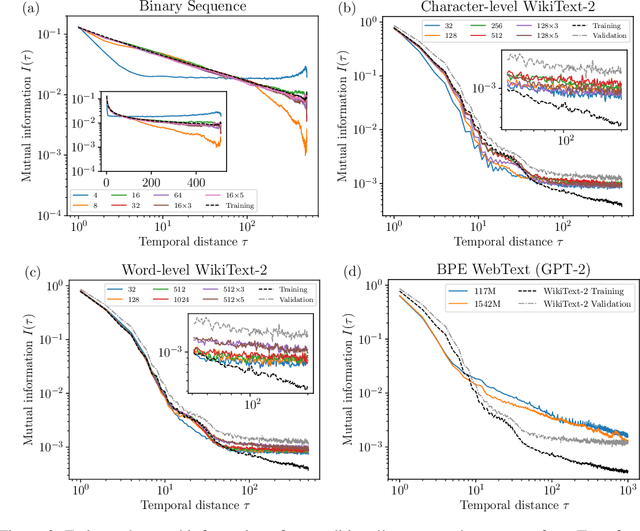

Sequence models assign probabilities to variable-length sequences such as natural language texts. The ability of sequence models to capture temporal dependence can be characterized by the temporal scaling of correlation and mutual information. In this paper, we study the mutual information of recurrent neural networks (RNNs) including long short-term memories and self-attention networks such as Transformers. Through a combination of theoretical study of linear RNNs and empirical study of nonlinear RNNs, we find their mutual information decays exponentially in temporal distance. On the other hand, Transformers can capture long-range mutual information more efficiently, making them preferable in modeling sequences with slow power-law mutual information, such as natural languages and stock prices. We discuss the connection of these results with statistical mechanics. We also point out the non-uniformity problem in many natural language datasets. We hope this work provides a new perspective in understanding the expressive power of sequence models and shed new light on improving the architecture of them.