 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiWOZ 2.4: A Multi-Domain Task-Oriented Dialogue Dataset with Essential Annotation Corrections to Improve State Tracking Evaluation
Paper and Code
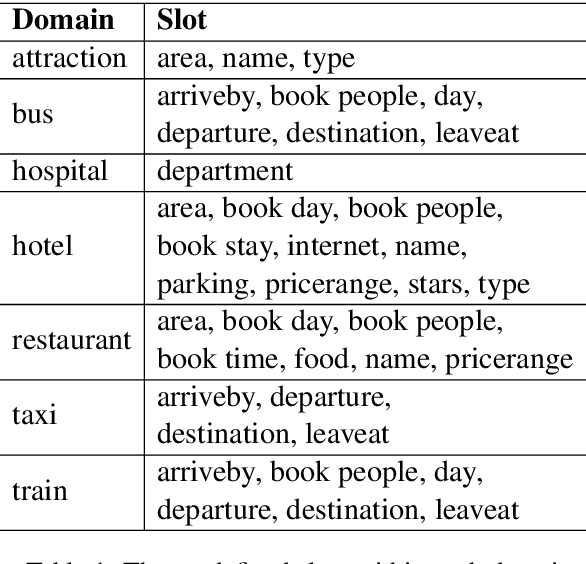
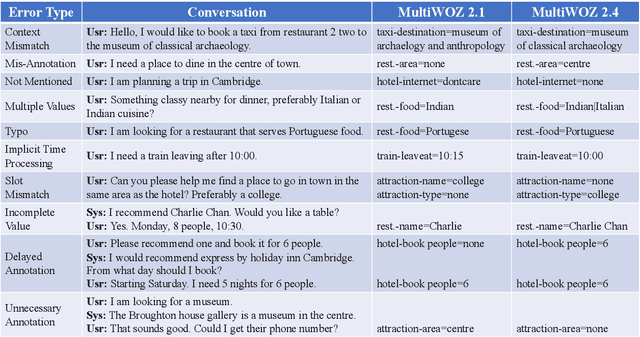


The MultiWOZ 2.0 dataset was released in 2018. It consists of more than 10,000 task-oriented dialogues spanning 7 domains, and has greatly stimulated the research of task-oriented dialogue systems. However, there is substantial noise in the state annotations, which hinders a proper evaluation of dialogue state tracking models. To tackle this issue, massive efforts have been devoted to correcting the annotations, resulting in 3 improved versions of this dataset (i.e., MultiWOZ 2.1-2.3). Even so, there are still lots of incorrect and inconsistent annotations. This work introduces MultiWOZ 2.4, in which we refine all annotations in the validation set and test set on top of MultiWOZ 2.1. The annotations in the training set remain unchanged to encourage robust and noise-resilient model training. We further benchmark 8 state-of-the-art dialogue state tracking models. All these models achieve much higher performance on MultiWOZ 2.4 than on MultiWOZ 2.1.