 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Paper and Code


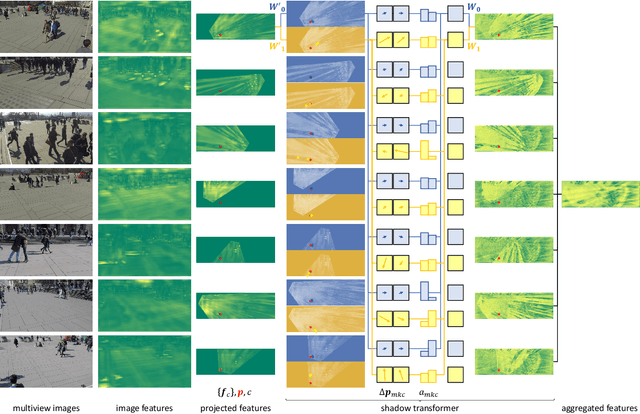

Multiview detection incorporates multiple camera views to deal with occlusions, and its central problem is multiview aggregation. Given feature map projections from multiple views onto a common ground plane, the state-of-the-art method addresses this problem via convolution, which applies the same calculation regardless of object locations. However, such translation-invariant behaviors might not be the best choice, as object features undergo various projection distortions according to their positions and cameras. In this paper, we propose a novel multiview detector, MVDeTr, that adopts a newly introduced shadow transformer to aggregate multiview information. Unlike convolutions, shadow transformer attends differently at different positions and cameras to deal with various shadow-like distortions. We propose an effective training scheme that includes a new view-coherent data augmentation method, which applies random augmentations while maintaining multiview consistency. On two multiview detection benchmarks, we report new state-of-the-art accuracy with the proposed system. Code is available at https://github.com/hou-yz/MVDeTr.