Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple protein feature prediction with statistical relational learning
Paper and Code
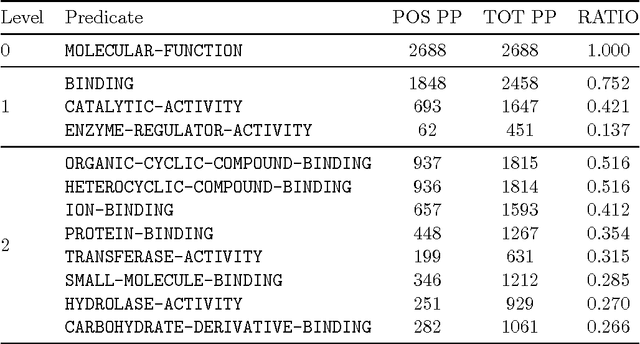
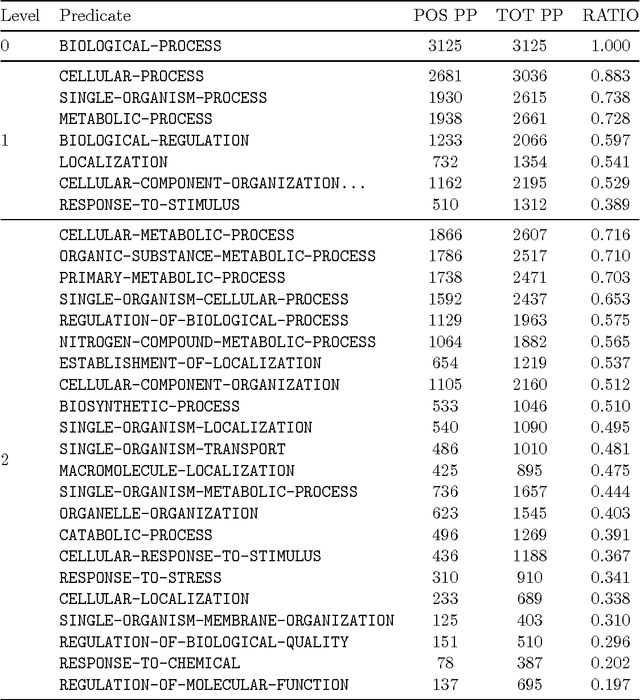


High throughput sequencing techniques have highly impactedon modern biology, widening the gap between sequenced andannotated data. Automatic annotation tools are thereforeof the foremost importance to guide biologists' experiments. However, most of the state-of-the-art methods rely on annotation transfer, offering reliable predictions only in homology settings. In this work we present a novel appraoch to protein feature prediction, which exploits the Semanti Based Regularization to inject prior knowledge in the learning process. The experimental results conducted on the yeast genome show that the introduction of the constraints positively impacts on the overall prediction quality.
View paper on