 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple F0 Estimation in Vocal Ensembles using Convolutional Neural Networks
Paper and Code
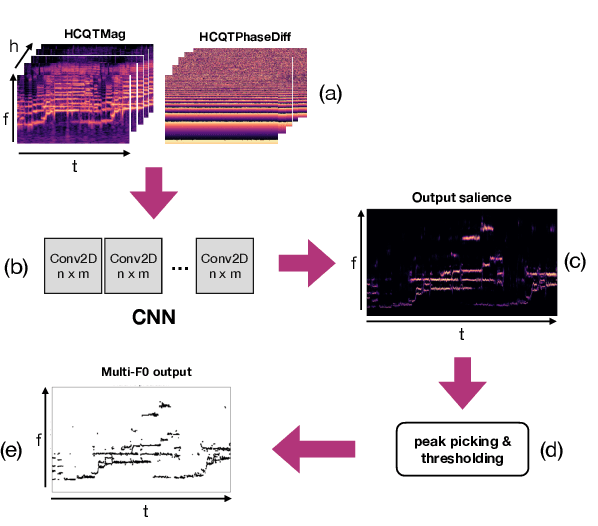
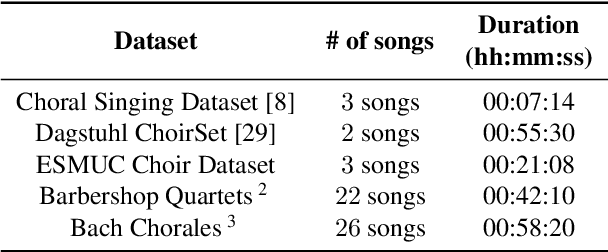
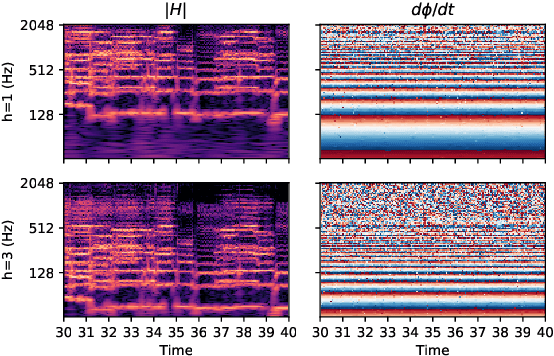
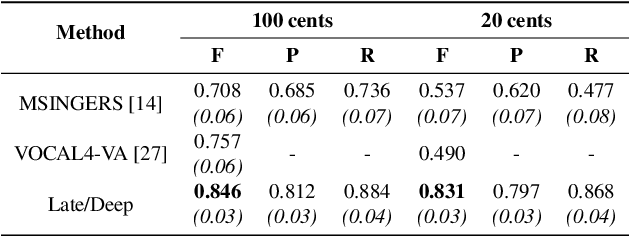
This paper addresses the extraction of multiple F0 values from polyphonic and a cappella vocal performances using convolutional neural networks (CNNs). We address the major challenges of ensemble singing, i.e., all melodic sources are vocals and singers sing in harmony. We build upon an existing architecture to produce a pitch salience function of the input signal, where the harmonic constant-Q transform (HCQT) and its associated phase differentials are used as an input representation. The pitch salience function is subsequently thresholded to obtain a multiple F0 estimation output. For training, we build a dataset that comprises several multi-track datasets of vocal quartets with F0 annotations. This work proposes and evaluates a set of CNNs for this task in diverse scenarios and data configurations, including recordings with additional reverb. Our models outperform a state-of-the-art method intended for the same music genre when evaluated with an increased F0 resolution, as well as a general-purpose method for multi-F0 estimation. We conclude with a discussion on future research directions.